UCCL-Tran: An Extensible Software Transport Layer for GPU Networking

By: Yang Zhou*, Zhongjie Chen*, Ziming Mao, ChonLam Lao, Shuo Yang, Pravein Govindan Kannan, Jiaqi Gao, Yilong Zhao, Yongji Wu, Kaichao You, Fengyuan Ren, Zhiying Xu, Costin Raiciu, Ion Stoica — May 26, 2025
UCCL-Tran is a software-only extensible transport layer for GPU networking. It is designed to be fast and extensible to meet the challenging requirements of modern ML/LLM workloads.
UCCL-Tran achieves up to 3.3x higher performance over NCCL on AWS, which translates into up to 1.4× speedup for two ML applications (DeepSeek-V3 Serving, ResNet distributed training). UCCL-Tran provides a flexible and extensible framework that allows developers to readily deploy custom transport protocols in software tailored to the latest ML workloads. For example, UCCL-Tran supports a receiver-driven protocol EQDS to handle network incast in MoE-like workloads, achieving 4.9× better message tail latency over InfiniBand built-in transport. UCCL-Tran is also compatible with many NIC vendors (Nvidia, AMD, AWS, etc.), preventing vendor lock-in. More details can be found in our UCCL-Tran paper and GitHub repo.
Fast-evolving ML workloads outpaces slow-evolving networking
ML workloads and their requirements for networking are evolving rapidly. Less than ten years ago, deep neural networks only had millions of parameters, and were trained atop hundreds of CPUs/GPUs with parameter servers or allreduce collective communication. After five years, large language models (LLMs) began to surge with billions of parameters, and were trained atop thousands of more powerful GPUs with multi-level parallelism and diverse collectives like allreduce, allgather, and reduce-scatter. In the recent two years, large-scale LLM serving has become the norm; prefill-decode disaggregation has emerged as an efficient serving technique, requiring fast peer-to-peer communication. This year, serving Mixture-of-Experts (MoE) models like DeepSeek-V3 became very popular, featuring challenging all-to-all communication among hundreds of GPUs.
However, networking techniques especially the host network transport on RDMA NICs are hard to adapt and evolve to better suit the needs of ML workloads. Essentially, hardware changes are time-consuming and take much longer time than software changes. The mismatch between the application and existing hardware often translates into poor performance.
Operational evidence from several large-scale deployments underscores the problem. Meta found that DCQCN—the congestion-control scheme implemented in most datacenter NICs—performed poorly for large-language-model (LLM) training traffic, which exhibits low flow entropy and burstiness 1. As a result, Meta disabled NIC-level congestion control entirely. DeepSeek reached a similar conclusion while serving mixture-of-experts (MoE) models: it disabled congestion control to sustain the required all-to-all exchanges 2, but doing so left the RDMA fabric vulnerable to deadlocks, head-of-line blocking, and pervasive congestion. Alibaba diagnosed a different bottleneck: collective communication slowed dramatically because each RDMA connection could use only a single path, producing severe flow collisions 3. Their remedy was a rail-optimized dual-plane topology—a substantial re-engineering effort undertaken solely to compensate for limitations of existing NIC transport. Collectively, these experiences highlight the need for transport mechanisms that can be extended or replaced in software, without waiting for a new generation of hardware.
UCCL-Tran: a software-only extensible transport layer for GPU networking
UCCL-Tran is a software-only extensible transport layer for GPU networking. It is designed to address the challenges of fast-evolving ML workloads and the limitations of existing RDMA NICs. UCCL-Tran provides a flexible and extensible framework that allows developers to implement custom transport protocols and congestion control algorithms tailored to the specific needs of each ML workload.
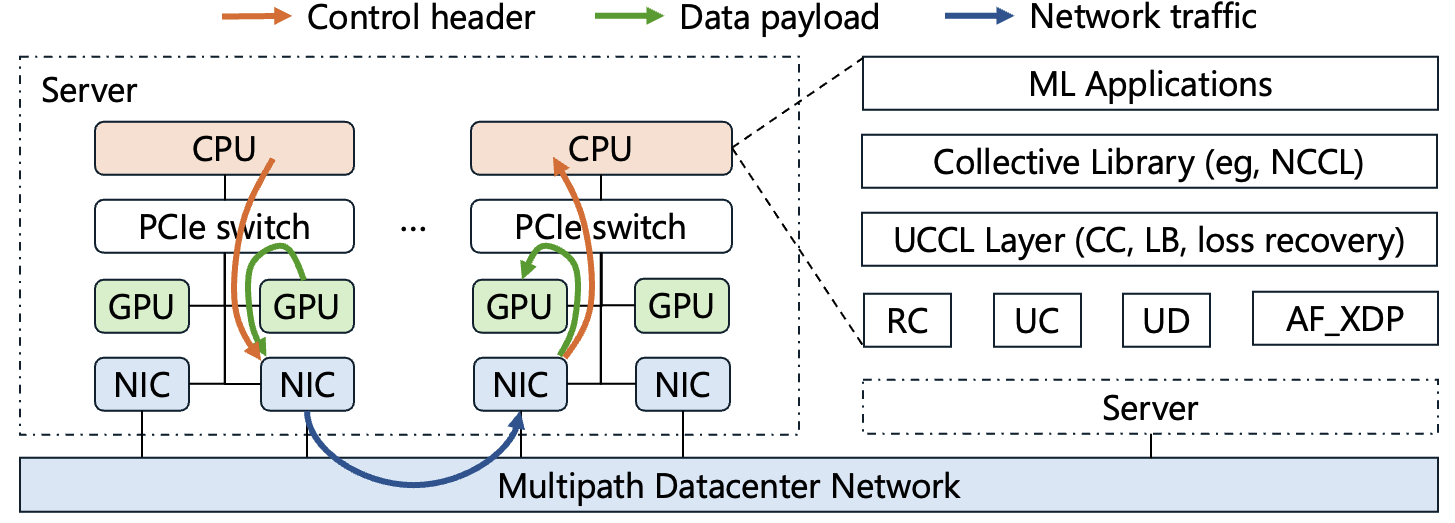 Figure 1: UCCL-Tran architecture.
Figure 1: UCCL-Tran architecture.
Key challenges addressed by UCCL-Tran
Decouple the data and control paths for existing RDMA NICs
The overall goal of separating the control path and the data path is to enable running extensible transport on the CPU, while efficiently transferring data to/from GPUs in a GPUDirect manner. This goal has three specific aspects: (1) We should involve as little control logic as possible in the data path to let the CPU make more transport decisions, like Congestion Control (CC) and packet reliability. (2) We must achieve GPUDirect for the data path efficiency. (3) We should support heterogeneous RDMA NICs. For example, NVIDIA NICs support UC, while Broadcom and AWS EFA do not.
Achieve hardware-level performance for software control path
Supporting hardware-level performance for software control path is challenging, as a single GPU server could have 8×400 Gbps RDMA NICs, totaling 3.2 Tbps bandwidth bidirectionally; the next generation RDMA NIC will achieve 800 Gbps, reaching a 6.4 Tbps bandwidth. As a reference, Google’s software transport Snap can handle 80 Gbps traffic on a CPU core (though they do not use RDMA NICs). Our goal is to use 1 CPU core to handle 400G unidirectional traffic.
Support multiple vendor NICs and their different capabilities
Datacenters usually consist of multiple generations and vendors of RDMA NICs due to continuous expansion, cost optimization, and to avoid vendor lock-in. In practice, UC is not always supported across different RDMA NIC vendors, e.g., Broadcom. While NVIDIA, Broadcom, and AMD all have 400 Gbps RDMA NICs for ML, they come with subtly different control path logic like packet reliability and CC; this heterogeneity reduces achievable bandwidth by 2-33× when communicating between NICs from different generations/vendors, as reported by Alibaba. Instead, if we can extensibly align these NICs’ control path logic in software, we could avoid such a severe performance drop.
Core UCCL-Tran Insights
1. Moving control paths to CPU with more stored states and faster processing
UCCL-Tran’s architecture revolves around a clean separation of control logic and data movement. All decisions that benefit from rapid iteration—such as congestion control, path selection, and loss recovery—run in user space on the CPU, while the heavy‐weight transfer of tensor data stays on the NIC/GPU data path via GPUDirect DMA. This design places three concrete requirements on the transport substrate: minimal hardware intervention in the data path, direct GPU memory access, and compatibility with the diverse queue-pair (QP) types offered by different RDMA vendors. Whenever available, UCCL-Tran chooses the Unreliable Connection (UC) QP because it offers NIC-side segmentation/reassembly yet leaves congestion control and reliability to software. For NICs that lack UC, it falls back to Reliable Connection (RC) with hardware CC disabled, or, as a last resort, Unreliable Datagram (UD), accepting higher CPU cost in exchange for full software control.
 Figure 2: Moving control paths to CPU via RDMA UC/RC.
Figure 2: Moving control paths to CPU via RDMA UC/RC.
 Figure 3: Moving control paths to CPU via RDMA UD.
Figure 3: Moving control paths to CPU via RDMA UD.
Operating over UD, however, raises practical issues because the NIC no longer reassembles multi-packet messages. UCCL-Tran resolves this in two steps. First, it uses scatter–gather lists so the NIC merges the control header (allocated in host memory) and the data payload (resident in GPU memory) into a single packet on transmit and splits them on receive, ensuring the two always “fate-share” with respect to loss and ordering. Second, on the GPU side, out-of-order payloads must be re-stitched into contiguous message buffers; instead of launching an extra kernel, UCCL-Tran fuses a lightweight scatter-memcpy routine into the reduction kernels. The additional GPU bandwidth consumed is bounded by network throughput and therefore negligible on modern accelerators. Together, these design choices let UCCL-Tran present a uniform, extensible control plane across heterogeneous hardware while preserving line-rate data delivery to GPUs.
2. Harnessing multi-path for avoiding path collision
One of the key motivations for GPU network extensibility is to harness the multipath capacity of modern datacenter networks. UCCL-Tran achieves this by using multiple UC, RC, or UD QPs. Basically, network traffic from different QPs will likely go through different network paths, as both RoCE and Infiniband usually use ECMP (Equal-Cost Multi-Path) for multipath routing with source and destination QP numbers as the hash inputs. For UC and RC, UCCL-Tran by default uses 256 QPs, which provides maximum 256 different network paths as used by recent transport research. For UD, UCCL-Tran uses a much smaller number of QPs by combining different source and destination QPs. For example, 16 source UD QPs and 16 destination UD QPs will provide maximum 16×16=256 different network paths, because for connection-less UD, each source QP can send packets to any destination QP.
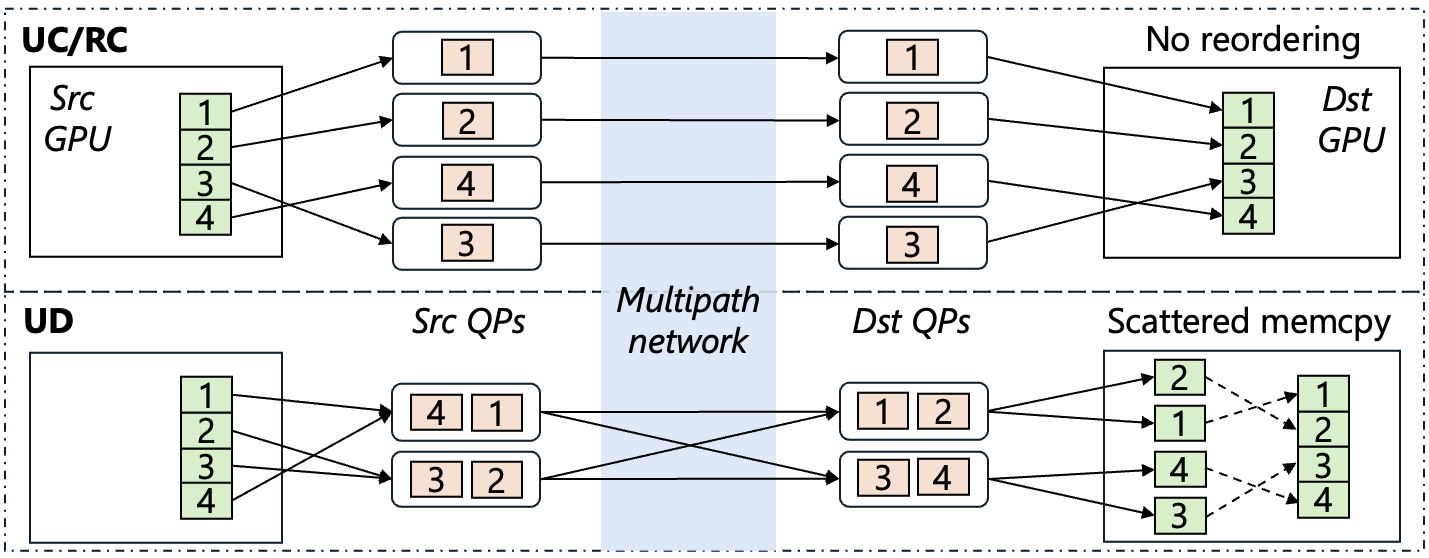 Figure 4: Harnessing multi-path.
Figure 4: Harnessing multi-path.
Handling out-of-order packets: Many factors could cause out-of-order packet delivery, including multipathing, packet loss, and the unpredictable multi-QP scheduler in RDMA hardware. Existing RDMA NICs perform poorly when handling out-of-order packets, as they cannot maintain large reordering buffers and states due to limited on-chip SRAM constraints. In contrast, UCCL-Tran is able to handle out-of-order packets efficiently thanks to its software flexibility and separation of data and control paths. Different from TCP, UCCL-Tran maintains its packet reordering buffers in the GPU memory and lets the NIC directly DMA network data there. For UC/RC, the reordering buffers are individual data chunks, and the sender CPU specifies in-order chunk addresses when posting verbs. For UD, the reordering buffers are individual packet payloads, and the GPU reduction kernel reorders packets when copying them into the transport buffers.
3. Towards efficient software transport for ML networking
Run-to-completion execution: Each UCCL-Tran engine thread runs RX, TX, pacing, timeout detection, and retransmission functionalities for a set of connections in an efficient run-to-completion manner. UCCL-Tran employs Deficit Round Robin (DRR) scheduling to fairly multiplex one engine thread among multiple functionalities and connections.
Connection splitting: To handle 400+ Gbps traffic per NIC more efficiently, UCCL-Tran pivots away from the Flor design of a single CPU core for one connection, but leverages multiple cores for one connection with connection splitting. Basically, UCCL-Tran equally partitions the 256 QPs among all engine threads responsible for a specific NIC; each engine thread gets its own connection states for CC and LB, forming a sub-connection. Within each sub-connection, UCCL-Tran uses RDMA SRQ and SCQ (Shared Recv/Completion Queues) to reduce the overhead when polling multiple recv and completion queues. The application threads atop the UCCL-Tran plugin are responsible for choosing the least-loaded engine (e.g., the engine with the least unconsumed messages) when dispatching messages via SHM. In this way, UCCL-Tran could scale transport processing of a single connection to multiple cores, and handle transient load imbalance among CPUs at runtime.
Control coalescing: There is an inherent tradeoff between the control decision granularity and software transport efficiency. One could run CC, LB, and reliability logic for each packet to achieve precise control of the transport behaviors, at the cost of consuming more CPU cores. Alternatively, one could relax the control granularity by coalescing several same-path packets and making control decisions together, thus with lower CPU consumption. For UC/RC, this also means an RDMA write could directly transmit several packets as a single data chunk, leveraging NIC-offloaded segmentation and reassembly. UCCL-Tran employs this control coalescing design with 32KB chunk size as default, striking a balanced tradeoff. Under this chunk size, UCCL-Tran can saturate 400 Gbps, unidirectional bandwidth with 1 CPU core, while not severely disrupting transport behaviors/performance. Nevertheless, UCCL-Tran could also adaptively adjust chunk size based on the congestion level, e.g., switching to a small chunk size to make more precise control when congestion window (cwnd) drops below a threshold or severe packet loss happens.
Chained posting: UD does not support NIC offloading for segmentation and reassembly, thus it incurs more Memory-Mapped Input/Output (MMIO) writes than UC/RC when issuing send/recv verbs (e.g., for individual packets). To reduce such overhead, UCCL-Tran leverages the chained posting feature of RDMA NICs to issue one MMIO write for posting up to 32 send/recv verbs. Concretely, the WQEs of these 32 verbs are chained together through the next pointer in previous WQEs, and get posted to the RDMA NIC in one MMIO write.
Evaluation
To demonstrate the versatility of this interface and the power of UCCL-Tran’s extensibility, we use three case studies. These case studies show that UCCL-Tran effectively enables transport-layer innovations that would otherwise require costly, time-consuming changes to today’s network stack.
-
We implement a multipath transport protocol that mitigates flow collisions by leveraging packet spraying—randomly sending packets from a single connection across different paths. This transport achieves 3.3 × higher throughput for collective communication over AWS’s SRD on EFA NICs.
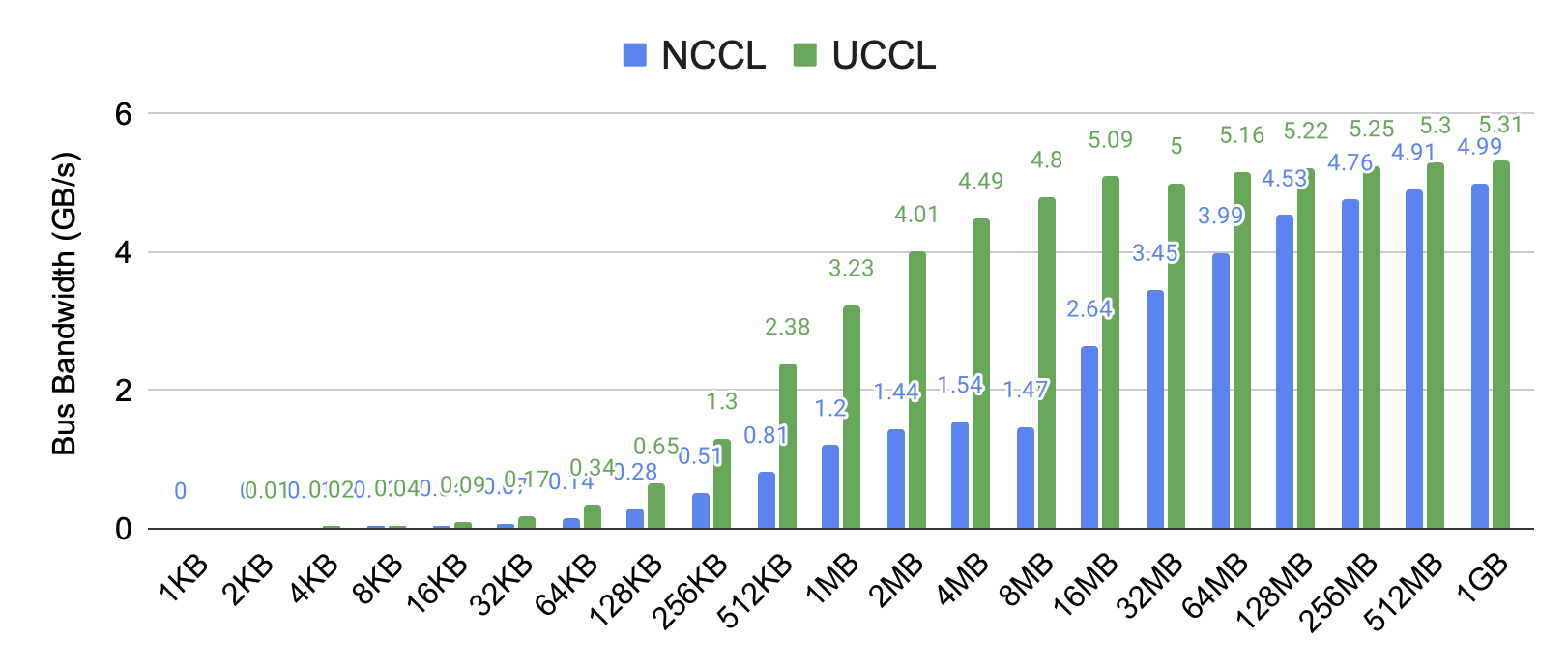 Figure 5: UCCL-Tran vs. NCCL on 4 AWS p4d.24xlarge VMs (NVLink disabled to simulate a larger testbed).
Figure 5: UCCL-Tran vs. NCCL on 4 AWS p4d.24xlarge VMs (NVLink disabled to simulate a larger testbed).
-
We implement the receiver-driven EQDS 4 protocol to handle network incast in MoE-like workloads, reducing message tail latency by 4.9 × compared with InfiniBand’s built-in transport.
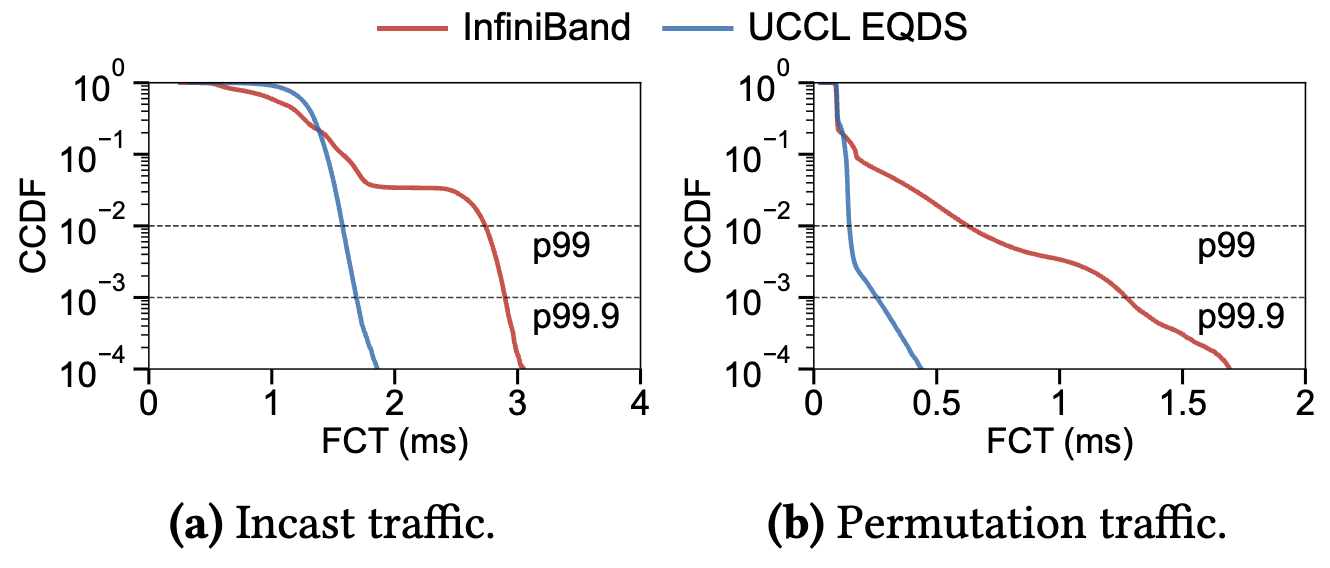 Figure 6: Complementary CDF of FCT (Flow Completion Time) on Nvidia ConnectX-7 InfiniBand NICs when co-locating 15-to-1 incast traffic and permutation traffic.
Figure 6: Complementary CDF of FCT (Flow Completion Time) on Nvidia ConnectX-7 InfiniBand NICs when co-locating 15-to-1 incast traffic and permutation traffic.
-
We implement selective retransmission for efficient loss recovery and demonstrate its superiority over RDMA hardware transport under packet loss. Prior work has reported that RDMA hardware transport can only keep 20-40% of throughput under 0.1% packet loss 5, while UCCL-Tran can keep 60-80%.
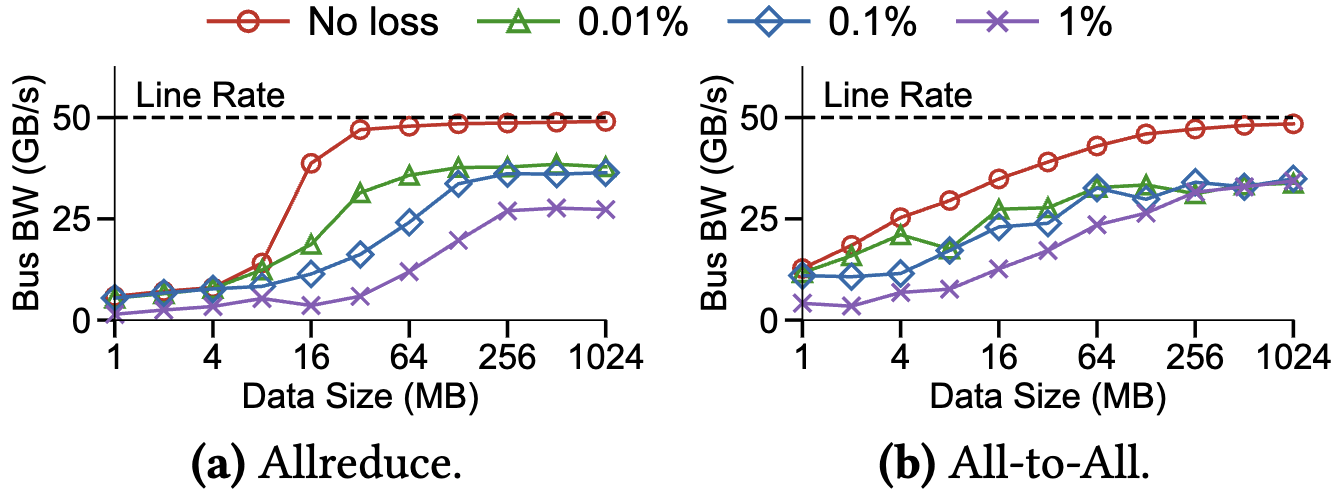 Figure 7: Performance comparison on Nvidia ConnectX-7 InfiniBand NICs under different instrumented packet loss rates.
Figure 7: Performance comparison on Nvidia ConnectX-7 InfiniBand NICs under different instrumented packet loss rates.
Future development plan
Our future work has three focuses:
- Enabling dynamic membership, so GPU servers can join or leave an ongoing job without interruption
- Introducing GPU-initiated, vendor-agnostic network peer-to-peer communication that spans NVIDIA, AWS EFA, Broadcom, and other NICs, thereby supporting both MoE all-to-all exchanges and high-rate KV-cache transfers in parameter-disaggregated deployments
- Rearchitecting NCCL to unlock latent network-hardware capabilities through a scalable, efficient CPU proxy, low-cost asynchronous collectives that preserve compute-communication ordering guarantees, and device kernels implemented in the vendor-neutral Triton language.
Getting involved
UCCL-Tran is an open-source project, and we welcome contributions from the community. You can find the source code on github.com/uccl-project/uccl. We encourage you to try UCCL-Tran, report issues, and contribute to the project.
Footnotes
-
Gangidi, Adithya, et al. “Rdma over ethernet for distributed training at meta scale.” Proceedings of the ACM SIGCOMM Conference 2024. Paper link. ↩
-
Liu, Aixin, et al. “Deepseek-v3 technical report.” arXiv preprint arXiv:2412.19437 (2024). Paper link. ↩
-
Qian, Kun, et al. “Alibaba hpn: A data center network for large language model training.” Proceedings of the ACM SIGCOMM Conference 2024. Paper link. ↩
-
Olteanu, Vladimir, et al. “An edge-queued datagram service for all datacenter traffic.” Proceedings of the USENIX OSDI Conference 2022. Paper link. ↩
-
Li, Qiang, et al. “Flor: An open high performance RDMA framework over heterogeneous RNICs.” Proceedings of the USENIX OSDI Conference 2023. Paper link. Figure 7(b): curves of “lossy,1/1024” and “lossless,1/1024”. ↩