When Your AI Training Cluster Crashes at 3 AM: How TrainMover Cuts Recovery Time to 20 Seconds

By: the UCCL team
Date: May 18, 2026
Training a large language model is a weeks-long marathon across thousands of GPUs. When something breaks — and something always breaks — every GPU stops and waits. This post walks through a paper accepted at OSDI '26 — TrainMover — that cuts recovery downtime to ~20 seconds with zero additional GPU memory. The core insight is surprisingly clean, and the results are hard to argue with.
The UCCL team recently reads through the TrainMover paper, accepted at OSDI ‘26, and thought it was worth writing up. The problem it tackles — how to recover a large training job after a machine failure — sounds unglamorous. But once you work through the numbers, it becomes clear this is one of the more consequential systems problems in large-scale ML right now.
Here is what the paper argues, and why we think it’s worth paying attention to.
Part 1: The Scale of the Problem
Modern LLMs are trained at extraordinary scale. GPT-3 required 1,024 GPUs running for 34 days. Llama 3 used 16,000 H100 GPUs for 54 days 1. Meta, xAI, and others are scaling to 100K+ GPUs 2 3. These jobs run on tightly synchronized distributed training frameworks like Megatron-LM and DeepSpeed, where every GPU must exchange intermediate results before every training iteration.
This creates a brutal property: a single failure halts the entire cluster.

In tightly synchronized distributed training, every GPU must exchange data every iteration. When a single GPU fails, every other GPU in the cluster goes idle until recovery completes.
And failures are not rare. Alibaba’s FALCON 4 reports that 60% of large-scale training jobs experience hardware slowdowns. Meta reports that a 1,024-GPU job has a mean-time-to-failure (MTTF) of just 7.9 hours 5. At 16,000 GPUs, that drops to 2.7 hours 1.
The financial stakes are real. Training across 16K GPUs with AWS pricing costs $1.44M per day 6. A single interruption on an 8,192-GPU job — even with a fully automated recovery stack 1 — incurs 6.47 minutes of downtime.
What makes this especially alarming is how non-linearly the damage scales. A restart time of just a few minutes looks tolerable in isolation — but combine it with the MTTF of a large cluster and you get a collapse in effective throughput (ETTR) that accelerates as you add more GPUs.
ETTR is the fraction of time the cluster is actually making training progress, rather than restarting or recovering. An ETTR of 0.6 means 40% of your GPU time is wasted.
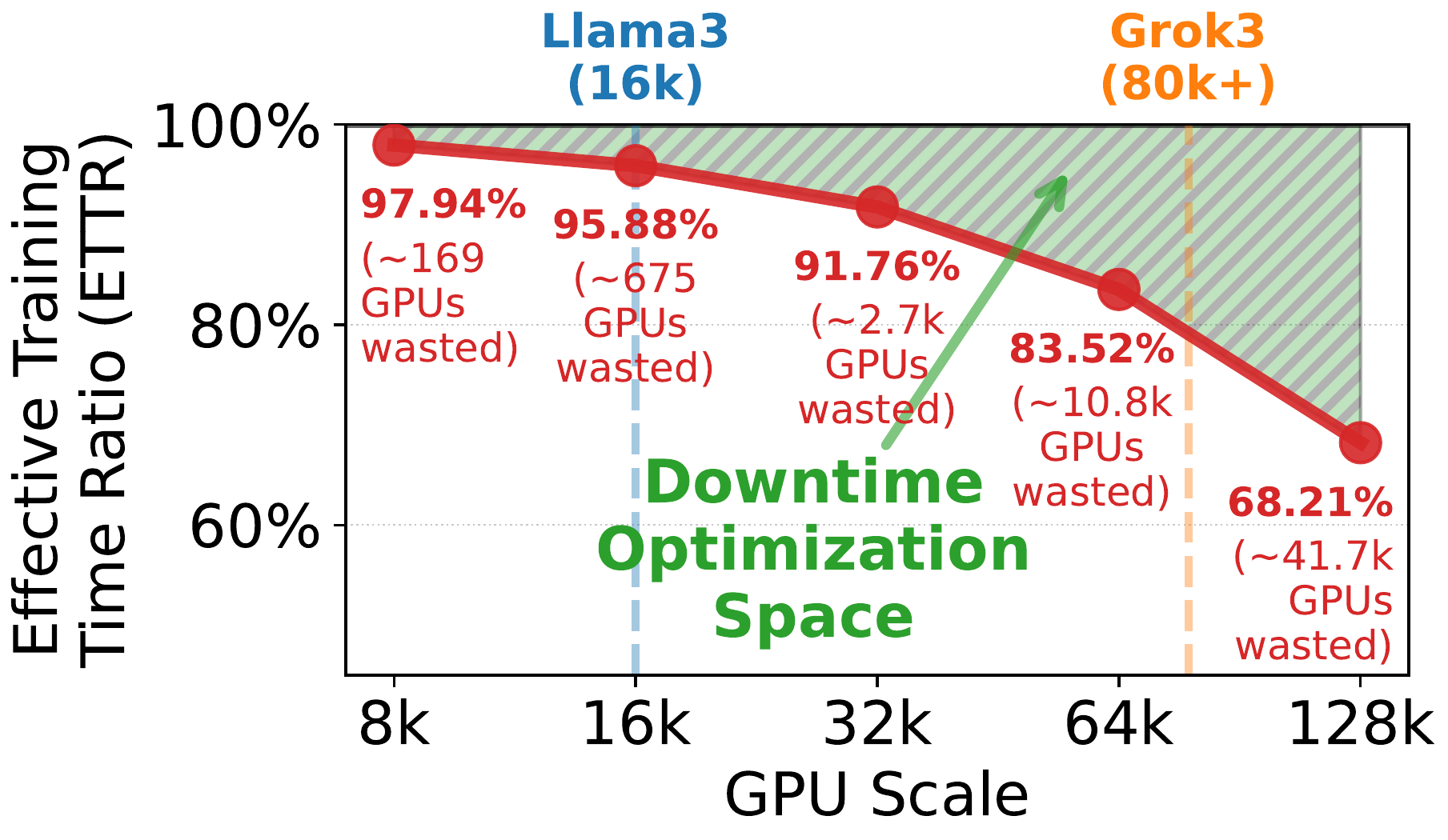
ETTR (Effective Training Time Ratio) as a function of cluster scale. Even a fixed per-interruption downtime causes throughput efficiency to collapse at production scales — Llama 3 (16K GPUs) and Grok 3 (80K+) operate deep in the red zone. Reducing downtime from minutes to seconds shifts the entire curve upward.
The paper frames this as the “downtime optimization space” — the gap between where training efficiency is today and where it could be with fast recovery. At 64K GPUs it represents $0.95M per day in wasted compute 3 7. That framing does a good job of making the stakes concrete.
Part 2: Why Is Recovery So Slow?
The paper opens with a careful breakdown of where restart time actually goes. When a machine fails, a healthy replacement must go through a full initialization sequence before it can rejoin the cluster:
| Phase | Avg. Time | % of Total |
|---|---|---|
| Job Stop & Cleanup | 0.52 min | 8.0% |
| Job Reschedule | 1.50 min | 23.2% |
| Checkpoint Loading | 1.56 min | 24.1% |
| NCCL Instantiation | 1.09 min | 16.8% |
| Cold Warmup (CUDA/JIT/etc.) | 1.80 min | 27.8% |
| TOTAL | 6.47 min | 100% |
Each phase has a distinct reason for being slow:
1. Job Stop & Cleanup (8.0%): The management system halts the training job and cleans up all servers — stopping the training framework, disconnecting remote storage, finalizing logs, and removing temporary data. Even this “bookkeeping” step costs over 30 seconds at scale.
2. Job Reschedule (23.2%): The affected machines are blacklisted and the job is rescheduled: candidate replacement servers are selected, health checks are run, the virtualized network is configured, containers are launched, and monitoring services are reinitialized. Nearly a quarter of total restart time goes to infrastructure coordination, not actual training recovery.
3. Checkpoint Loading (24.1%): Model weights and optimizer states — potentially hundreds of gigabytes — must be fetched from remote storage and loaded onto GPU memory. This scales directly with model size; loading a 175B-parameter model alone can take several minutes.
4. NCCL Instantiation (16.8%): Every parallelism dimension (DP, PP, TP) requires its own NCCL communication group. Forming these groups requires multi-round handshakes, topology discovery, and connection establishment across all nodes. At 1,000 machines, the number of connections scales as 1,000 × (# of CCL groups) × (# of channels per group) — all globally synchronized.
5. Cold Warmup (27.8%): Modern training frameworks rely on hardware-aware optimizations — JIT-compiled CUDA kernels, memory-layout specialization, fused operators — that only activate when real data arrives. The first training iteration is up to 6× slower than steady state, and this cascades serially across all pipeline stages.
What struck me about this breakdown is that every one of these phases happens on the critical path, with every other GPU in the cluster sitting idle. The paper makes this point early, and it’s the key motivating observation for everything that follows.
Part 3: Existing Approaches
The paper surveys two existing strategies, and honestly does a fair job characterizing their limitations.
The Straightforward Fix: Stop, Reschedule, Reinitialize
The simplest approach: when an interruption occurs, stop the job, remove the bad machine, bring in a healthy replacement, restore from checkpoint, restart. Simple, robust, and the dominant approach in production today. The cost is the full 6.47 minutes on the critical path, every time.
Runtime Reconfiguration — entering the picture
Researchers proposed elastic training systems — Oobleck 8, Parcae 9, ReCycle 10 — that let the job continue at reduced capacity (−1 machine) while a replacement joins (+1), avoiding a full restart.
This eliminates the top two rows of the table — Job Stop & Cleanup (8.0%) and Job Reschedule (23.2%) — since the job never stops. The paper’s critique, which I find convincing, is that this doesn’t actually reduce recovery time: the new joiner still must load a checkpoint, reinstantiate NCCL, and warm up from scratch, and every other machine still waits.
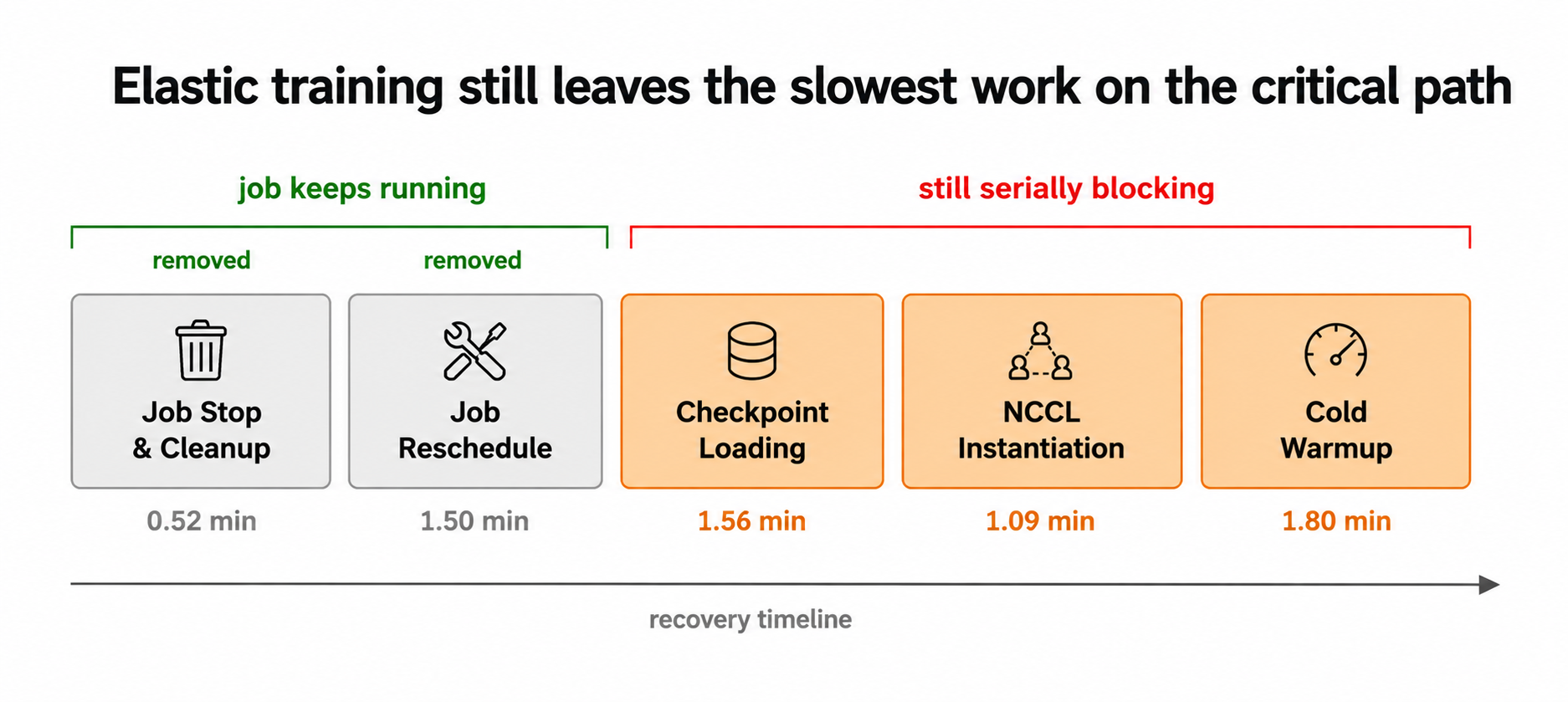
Elastic training removes Job Stop & Cleanup and Job Reschedule from the critical path, but Checkpoint Loading, NCCL Instantiation, and Cold Warmup — the heaviest phases — are still serially blocking every other GPU in the cluster.
The paper argues that any further progress requires moving work off the critical path entirely — before the failure ever happens. That’s the setup for TrainMover’s design.
Part 4: The Standby That Was Already There
Here is where the paper makes its core observation, and I think it’s the most interesting part of the argument.
Every large training cluster in production already keeps a pool of standby machines. Llama 3 1 was trained on 16K GPUs within a 24K-GPU cluster. Alibaba’s HPN 11 reserves 6% of GPUs as backup in each segment. ByteDance 7 allocates warm-standby pools based on the 99th percentile of historical GPU failure rates. The standby pool is not a luxury — it’s standard operating practice.
But these machines sit cold. The moment a failure happens, initialization starts from zero. The standby is physically present; it is logically absent.
TrainMover’s key insight: what if the standby didn’t start from zero? What if it had already compiled the CUDA kernels, pre-established its NCCL groups, and was ready to pull model state from surviving peer GPUs in memory — all before any failure occurred?
The paper calls this pre-warming the standby. When a failure happens, the replacement machine doesn’t fetch a checkpoint from remote storage or rebuild its communication topology — it has already done all of that. Joining the cluster takes ~20 seconds instead of 4+ minutes.
The question the paper then addresses is whether keeping that standby machine is actually worth the cost.
Part 5: All GPUs Training, or Keep Some on Standby?
The paper frames this as a resource allocation question, and the math is worth working through.
Say you have a budget of 32,008 GPUs. Two options:
- Option A: Put all 32,008 GPUs into training.
- Option B: Run 32,000 GPUs on training, keep 1 machine (8 GPUs) pre-warmed as a standby.
Option A looks obviously better — more raw compute. But it ignores downtime cost. At 32K-GPU scale, failures happen roughly every 54 minutes, and each one costs ~4.5 minutes of full-cluster idle time. Those lost GPU-hours accumulate fast.
Option B gives up 8 GPUs of raw capacity. But with TrainMover, that standby machine cuts recovery time from 4.5 minutes to ~20 seconds — at this scale, that reduction is equivalent to recovering roughly 2,400 GPU-hours per interruption.
Put differently: the 8 GPUs you gave up deliver the same effective throughput as 2,400 extra training GPUs would.
The trade-off isn’t always favorable — at small scale (say, 1K GPUs), failures are rare enough that the standby just sits idle. But the paper shows that past a certain cluster size, the calculus flips decisively. At 8K GPUs (MTTF = 3 hours), a single standby already pays for itself many times over. At 128K GPUs, the gap becomes enormous.
This is one of those arguments that’s simple once you’ve seen it, but genuinely non-obvious before. The right question isn’t “can I afford a standby machine?” — it’s “can I afford not to have one?”
The full design details are in the paper.
📄 TrainMover: An Interruption-Resilient Runtime for ML Training — OSDI ‘26 (arXiv version; final version to appear at OSDI ‘26)
Part 6: Results
TrainMover was evaluated on a 1,024-GPU testbed across models from GPT-2.7B to GPT-175B Dense and MoE models up to 5.12T parameters.
Downtime at Scale
| Scale | TrainMover (planned failure) | TrainMover (unexpected failure) | Megatron-LM |
|---|---|---|---|
| 32 GPUs | 11.5s | 19.6s | ~80s |
| 128 GPUs | 14.5s | 20.2s | ~190s |
| 256 GPUs | 15.5s | 20.4s | ~230s |
| 512 GPUs | 14.2s | 20.4s | ~260s |
| 1024 GPUs | 16.6s | 21.1s | ~300s |
The scale-insensitivity of TrainMover is what stands out here. Its downtime grows by less than 10 seconds from 32 → 1,024 GPUs, while Megatron-LM’s grows nearly 4×. The paper attributes this to a delta-based design: only the leaver–joiner connections are updated; every other machine in the cluster is untouched.
GPU-Hour Waste at Production Scale
Based on projections from the 1,024-GPU testbed measurements, at 64K GPUs deployment:
- TrainMover reduces wasted GPU hours by ~91% compared to Megatron-LM
- This saves ~2.1 million GPU-hours per week over Megatron-LM
Beyond Fault Tolerance
One section I didn’t expect to find interesting was the generalization of the migration primitive beyond hardware failures:
- Straggler eviction: a slow machine can be migrated out while training continues, losing only ~5% efficiency during the swap
- Load rebalancing: workloads can be redistributed periodically for locality or power balance, sustaining 97% ETTR even at 10-minute intervals
- Planned maintenance: driver updates and firmware patches become ~20-second live migrations instead of full restarts
The fact that the same mechanism handles all three cases is a nice sign of a well-abstracted design.
Full results for each use case are in the paper.
Key Takeaways
Interruptions are the norm, not the exception. The paper’s data — drawn from Meta’s Llama 3 training run, Alibaba’s production clusters, and ByteDance’s infrastructure — makes clear that failures at scale are not edge cases. They are the default operating condition.
The bottleneck has shifted from GPU count to recovery speed. When a cluster fails every few hours and each restart idles thousands of GPUs for minutes, raw compute headroom matters less than how quickly training resumes. The paper’s standby analysis makes this concrete: past a threshold cluster size, a single pre-warmed standby machine delivers more effective GPU-hours than many raw training GPUs ever could.
Zero memory overhead is non-negotiable at scale. GPU memory at training scale is fully packed. Any system requiring pre-allocated recovery buffers risks out-of-memory crashes or forces model size reductions. TrainMover’s delta-based CCL design keeps all preparation state in CPU memory and NVMe, touching GPU memory only at the final switchover moment.
The downtime–memory tradeoff is a false dichotomy. Prior systems accepted it as a given: fast recovery or full GPU utilization. TrainMover breaks this by identifying which steps must stay on the critical path — and moving everything else off it, with zero GPU overhead.
Conclusion
TrainMover achieves ~20 seconds of migration downtime at 1,024-GPU scale with zero memory overhead, handling both planned data center events and unexpected hardware failures. Accepted at OSDI ‘26 — according to TrainMover authors, their implementation will be open-sourced soon. For the full technical details, check the arXiv paper or find them at OSDI ‘26 in Seattle!
Questions or thoughts? Reach out to the TrainMover team!
References
Footnotes
-
A. Grattafiori et al., “The Llama 3 Herd of Models,” arXiv 2024. ↩ ↩2 ↩3 ↩4
-
xAI, “xAI’s Colossus Supercomputer Cluster,” 2024. ↩
-
M. Si et al., “Collective Communication for 100k+ GPUs,” arXiv 2025. ↩ ↩2
-
T. Wu et al., “FALCON: Pinpointing and Mitigating Stragglers for Large-Scale Hybrid-Parallel Training,” arXiv 2024. ↩
-
A. Kokolis et al., “Revisiting Reliability in Large-Scale Machine Learning Research Clusters,” arXiv 2024. ↩
-
AWS, “Amazon EC2 P5 Instance Pricing,” 2025. ↩
-
B. Wan et al., “Robust LLM Training Infrastructure at ByteDance,” EuroSys 2025. ↩ ↩2
-
I. Jang et al., “Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates,” SOSP 2023. ↩
-
J. Duan et al., “Parcae: Proactive, Liveput-Optimized DNN Training on Preemptible Instances,” NSDI 2024. ↩
-
S. Gandhi et al., “ReCycle: Resilient Training of Large DNNs using Pipeline Adaptation,” SOSP 2024. ↩
-
K. Qian et al., “Alibaba HPN: A Data Center Network for Large Language Model Training,” SIGCOMM 2024. ↩