How to Debug NCCL Performance Issues for ML Workloads?

By: UCCL Team — June 30, 2025
NCCL is the cornerstone in modern distributed machine learning workloads, connecting dozens to thousands of GPUs for synchronous collective communication. Any small performance problem happening in any GPU or any NIC would cause the overall communication slowdown, increasing the job completion time.
Running NCCL performantly in public cloud GPUs is challenging, mainly because of two reasons: 1) NCCL has so many environmental variables (up to 78 if you check NCCL‘s doc)---there are even some variables hidden inside the NCCL code not exposed out, and 2) networking layers such as RDMA can sometimes cause performance issues, while we users have very little control.
A NCCL Debugging Experience
A few weeks ago, we got access to six HGX VMs from a major public cloud provider. Each of the VMs has 8 H100 GPUs and 8 400Gbps Nvidia CX-7 NICs; these VMs are across two racks in a multi-tier RoCE network. We set up NCCL v2.23.4 and run all-reduce from NCCL-tests (9d26b84) across these six VMs. However, we got surprisingly low performance in our first attempt. It is far lower than what others have measured of 360GB/s bus bandwidth (busbw) 1. Our experience told us it is more likely to be the inter-node networking issues, especially as the intra-node NVLink gives good results when running collective within a single node.
We decided to only look at the inter-node networking issues by setting two environmental variables of NCCL: NCCL_P2P_DISABLE=1, NCCL_SHM_DISABLE=1. These two environment variables will enforce the NCCL collectives to only use the inter-node network, but not any intra-node networks like NVLink or local host shared memory. After disabling intra-node networks, we find that all-reduce is only able to achieve half of the NIC bandwidth, which is around 23GB/s (the NIC has 50GB/s bandwidth).
We then guess it might be that the NIC has two ports, while NCCL only uses one port? Following this guess, we try to increase the number of RDMA QPs so that the two ports can be fully utilized. We set the environmental variable NCCL_IB_QPS_PER_CONNECTION to 4. You can also use another hidden variable NCCL_NCHANNELS_PER_NET_PEER that should give a similar effect. With this setting, now NCCL is able to go beyond 25GB/s, but still far behind theoritical 50GB/s.
So what happens? Our next guess is that NCCL would require a larger number of SMs to catch up with the fast network. This number can be tuned by setting the number of NCCL channels: NCCL_MAX_NCHANNELS=8, NCCL_MIN_NCHANNELS=8. With this setting, we thought we should be able to reach 50GB/s; unfortunately, NCCL performance saturates at around 39GB/s. Furthermore, we find that NCCL busbw gets severe drops at large message sizes like 128MB.
What could be the possible cause of this low performance and bus bandwidth (busbw) drop at large messages? We finally guess it could be the RoCE network congestion in a typical datacenter networking topology Fattree 2. When multiple network flows come out of a rack switch to another rack switch, these flows may map to the same upper switch port and cause network congestion. Recall that each of the two flows could have up to 400Gbps traffic rate in ML workload, while a single switch port only has 400Gbps. If so, how are we gonna resolve this? Especially, we do not have any control over the NIC and switch settings in the public cloud.
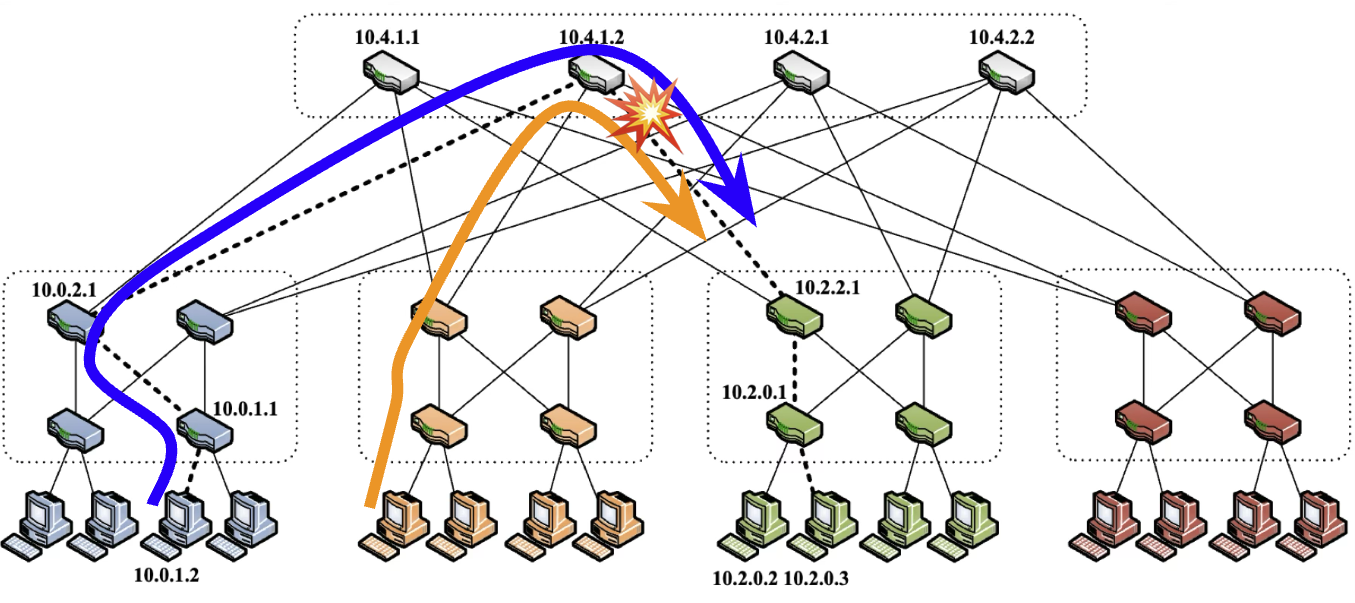 Figure 1: Network congestion could happen as each RDMA flow only goes through a single and fixed network path in RoCE, and two flows could collide on the same switch port.
Figure 1: Network congestion could happen as each RDMA flow only goes through a single and fixed network path in RoCE, and two flows could collide on the same switch port.
The final solution is that we leverage UCCL by simply setting another environmental variable NCCL_NET_PLUGIN=libnccl-net-uccl.so. The high-level idea here is that UCCL will leverage hundreds of network paths in a congestion-aware way to avoid the network congestion issues, therefore reaching the NIC bandwidth limit of 50GB/s. Another good thing about UCCL is that it does this in a transparent way, without modifying any piece of application code or even NCCL code.
Finally, with UCCL, we are able to avoid the NCCL performance drop at large messages and further improve its maximum throughput.
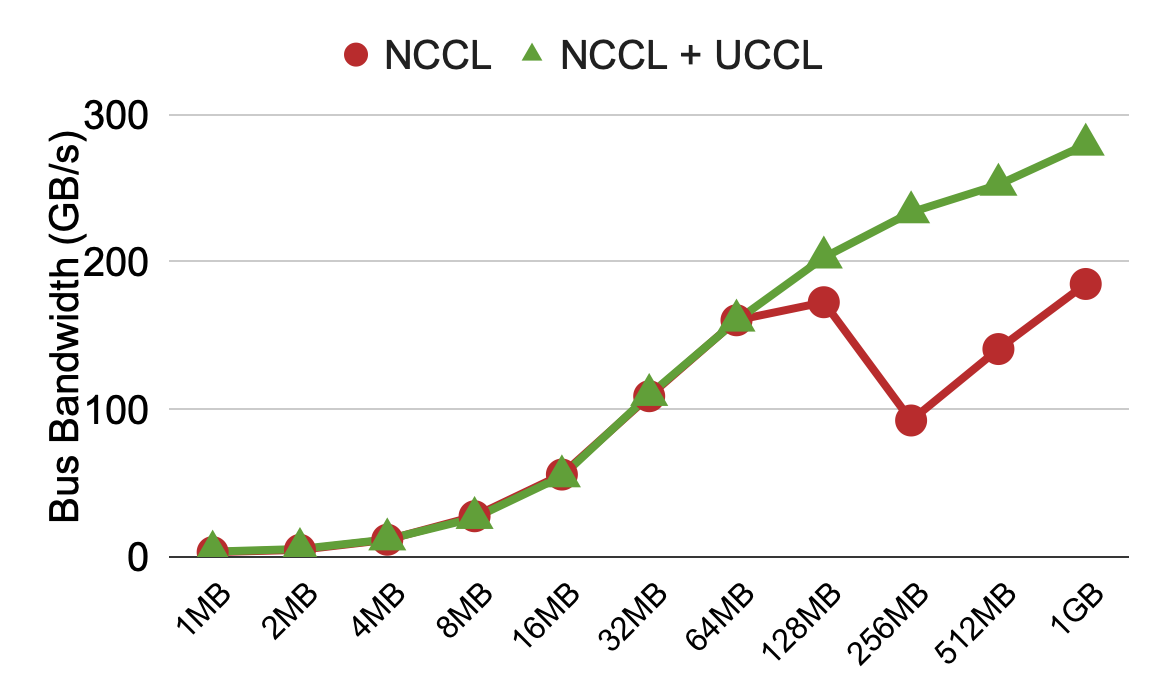 Figure 2: All-reduce performance across six machines, each with 8 H100 GPUs and 8 400G Nvidia NICs across two racks. Note that this measurement only uses 8 GPU SMs for NCCL/UCCL to leave enough SMs for ML applications; the measurement has NVLS off because of the GPU VM’s configuration issues on nv-fabricmanager.
Figure 2: All-reduce performance across six machines, each with 8 H100 GPUs and 8 400G Nvidia NICs across two racks. Note that this measurement only uses 8 GPU SMs for NCCL/UCCL to leave enough SMs for ML applications; the measurement has NVLS off because of the GPU VM’s configuration issues on nv-fabricmanager.
The Ultimate List
Based on UCCL team’s experience, here we summarize a list of highly relevant NCCL parameters that are worthy of tuning when hitting NCCL performance issues. Note that the list also includes some parameters we have not had time to cover.
- Looking at the networking performance:
NCCL_P2P_DISABLE=1, NCCL_SHM_DISABLE=1 - Number of QPs:
NCCL_IB_QPS_PER_CONNECTION, NCCL_NCHANNELS_PER_NET_PEER. - Number of channels:
NCCL_MAX_NCHANNELS, NCCL_MIN_NCHANNELS - Transport buffer and chunk sizes:
NCCL_P2P_NET_CHUNKSIZE=524288, NCCL_BUFFSIZE=8388608- These are extremely useful for AWS GPU VMs that use AWS EFA RDMA NICs
- PCIe relaxed ordering:
NCCL_IB_PCI_RELAXED_ORDERING- This could be useful when using GPU VMs rather baremetal machine
- Using the UCCL plugin:
NCCL_NET_PLUGIN=libnccl-net-uccl.so
Another Debugging Experience on AMD GPUs
Last week, we got access to a production cluster with AMD MI300X GPU + Broadcom 400G NICs, without any root privileges. We observe a similar performance drop for RCCL (AMD’s collective communication library) at large messages. We tried the UCCL plugin, and it effectively brought performance back.
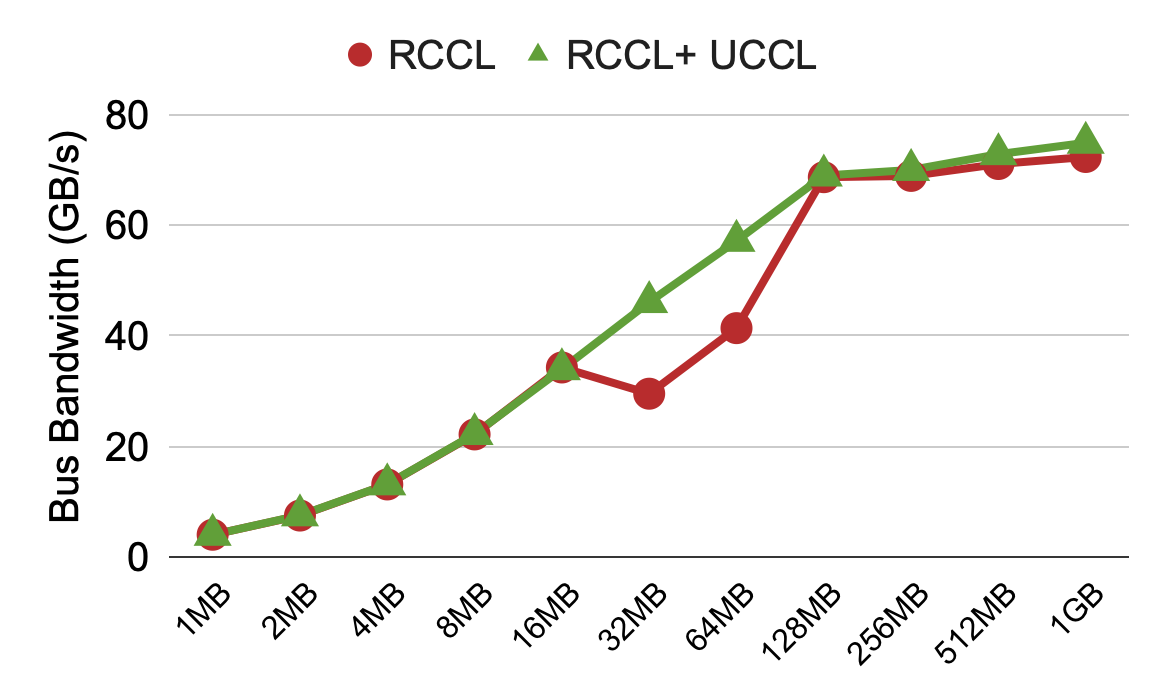 Figure 3: All-to-all performance across two machines, each with 4 AMD MI300X GPUs and 4 400G Broadcom NICs.
Figure 3: All-to-all performance across two machines, each with 4 AMD MI300X GPUs and 4 400G Broadcom NICs.
Summary
Debugging NCCL/RCCL performance is challenging, not only due to complex and hidden configurations, but also because of uncontrollable networking behaviors in public cloud deployments. Our UCCL team is here to help. We provide free consulting on performance-related NCCL/RCCL issues and the UCCL plugin to help you get rid of any network congestion issues.
UCCL is fully open-source at https://github.com/uccl-project/uccl, with many developers and maintainers from UC Berkeley Sky Computing Lab, the lab that once created Spark, Ray, and vLLM. We enthusiastically invite open-source developers to join and contribute to the UCCL project.
Footnotes
-
https://semianalysis.com/2024/12/22/mi300x-vs-h100-vs-h200-benchmark-part-1-training/#multi-node-rcclnccl-collectives-and-scale-out-network-benchmarks. ↩
-
Al-Fares, Mohammad, Alexander Loukissas, and Amin Vahdat. “A scalable, commodity data center network architecture.” ACM SIGCOMM computer communication review 38.4 (2008): 63-74. Paper link. ↩