A Practitioner Guide to AWS EFA Programming

By: Yang Zhou (UC Davis), Zhiying Xu (AWS), and the UCCL team
Date: April 13, 2026
We share a practical guide on how to program AWS EFA NICs for GPU communication workloads beyond NCCL.
We cover the EFA libibverbs interface, QP creation, address handling, RDMA write operations, and the critical challenges of ordering and atomics on EFA's multi-path SRD transport.
We also describe how to address these constraints with software-emulated atomics and receiver-side reordering, as implemented in UCCL.
Code: uccl-project/uccl/experimental/misc/efa_rdma_write.cc (Apache-2.0)
Introduction
AWS uses customized RDMA NICs called EFA (Elastic Fabric Adapter) across their GPU instances: Hopper-based p5, p5e, p5en VMs and Blackwell-based p6 VMs. Under the hood, EFA runs a proprietary multi-path transport protocol called SRD (Scalable Reliable Datagram), described in the SRD paper. SRD supports efficient multi-pathing to avoid single-path network congestion in datacenter networks, without relying on PFC (Priority Flow Control) which is notoriously hard to manage at large scale.
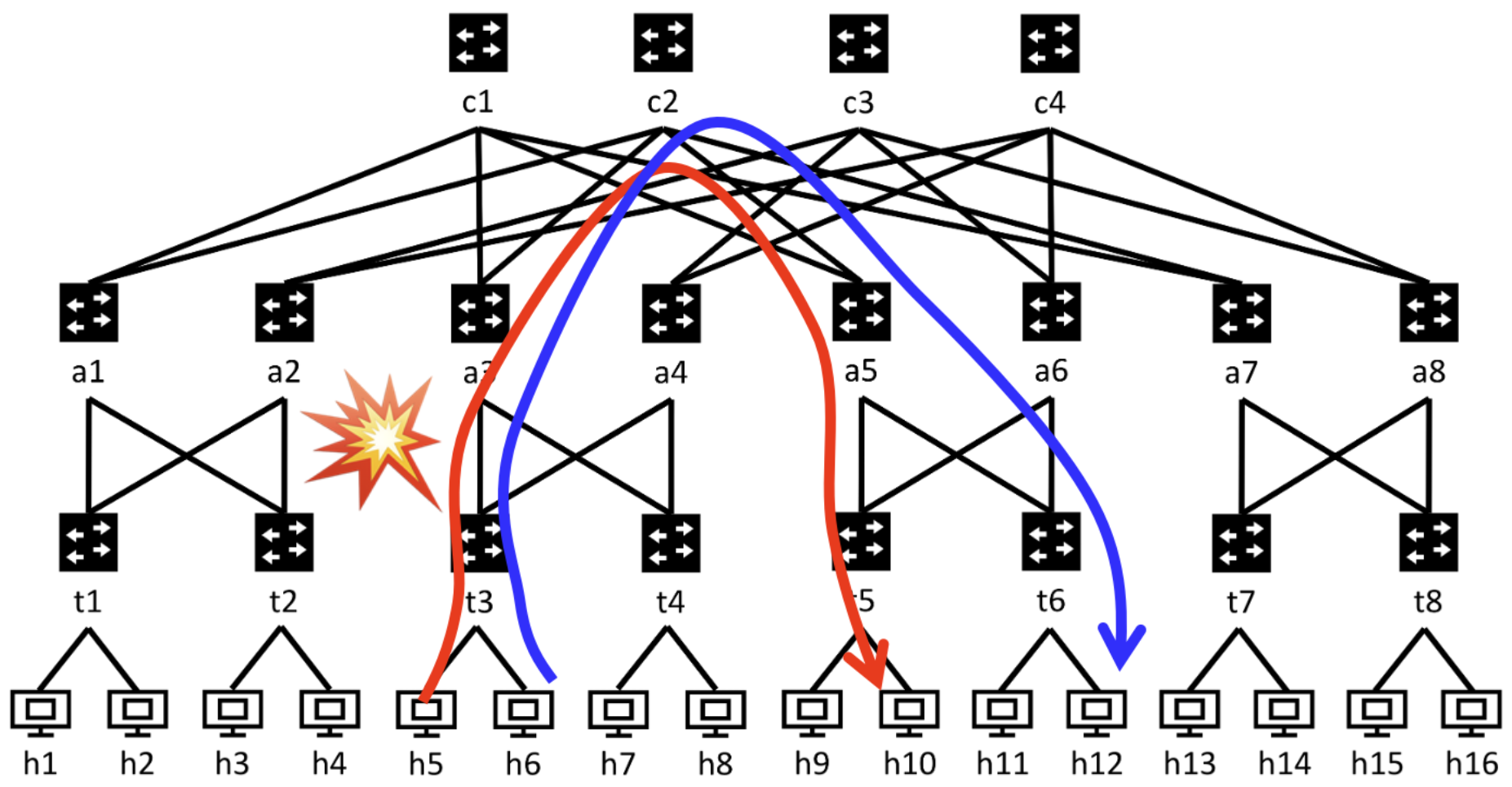
Left: Traditional single-path transport sends all packets along one fixed route, which is vulnerable to congestion at any single hop. Right: EFA's SRD multi-path transport dynamically sprays packets across multiple paths, balancing load and avoiding hotspots without PFC.
However, AWS EFA has different behaviors from conventional RDMA NICs like NVIDIA ConnectX-7 and Broadcom Thor-2, especially when used with GPUs. For a long time, most users did not need to directly program EFA NICs because they simply used NCCL with the aws-ofi-nccl plugin. However, new communication paradigms have recently emerged, such as GPU-initiated communication (e.g., DeepEP), point-to-point transfers (e.g., KV cache transfer for PD disaggregation, RL weight sync), and efficiently supporting them requires tight integration between GPU kernels and RDMA devices. We can no longer rely on one-size-fits-all NCCL collectives.
The UCCL team has done extensive investigation into AWS EFA NICs and built efficient EP and P2P libraries that support heterogeneous RDMA NICs, including EFA. In this blog, we share our experience with a heavy emphasis on how to use EFA for advanced non-NCCL use cases. We cover:
- EFA
libibverbsprogramming: QP creation, address handling, write operations - EFA ordering and atomics emulation: How to work around EFA’s lack of ordering guarantees and native atomics
- EFA performance characteristics: Strengths and tradeoffs compared to other RDMA NICs
EFA libibverbs Programming
EFA supports both libibverbs and libfabric. From our perspective, libfabric is essentially a wrapper around libibverbs. Most practitioners are more familiar with the libibverbs interface, since other RDMA NICs (NVIDIA ConnectX, Broadcom Thor-2) all use it as their primary programming interface. Thus, this blog focuses on the EFA libibverbs interface.
The full working example is available at efa_rdma_write.cc. You can compile and run it across two EFA-enabled instances to test RDMA write operations.
Creating EFA QPs
Creating an EFA QP differs from standard InfiniBand/RoCE QPs in several important ways. EFA uses the extended QP creation API with a vendor-specific EFA attribute struct:
struct ibv_qp_init_attr_ex qp_attr_ex = {0};
struct efadv_qp_init_attr efa_attr = {0};
qp_attr_ex.comp_mask = IBV_QP_INIT_ATTR_PD | IBV_QP_INIT_ATTR_SEND_OPS_FLAGS;
qp_attr_ex.send_ops_flags = IBV_QP_EX_WITH_RDMA_WRITE |
IBV_QP_EX_WITH_RDMA_WRITE_WITH_IMM |
IBV_QP_EX_WITH_RDMA_READ;
qp_attr_ex.cap.max_send_wr = 256;
qp_attr_ex.cap.max_recv_wr = 256;
qp_attr_ex.cap.max_send_sge = 1;
qp_attr_ex.cap.max_recv_sge = 1;
qp_attr_ex.pd = rdma_ctl->pd;
qp_attr_ex.sq_sig_all = 1;
qp_attr_ex.send_cq = ibv_cq_ex_to_cq(rdma_ctl->cq_ex);
qp_attr_ex.recv_cq = ibv_cq_ex_to_cq(rdma_ctl->cq_ex);
qp_attr_ex.qp_type = IBV_QPT_DRIVER;
efa_attr.driver_qp_type = EFADV_QP_DRIVER_TYPE_SRD;
efa_attr.sl = 8; // low-latency service level
struct ibv_qp* qp = efadv_create_qp_ex(
rdma_ctl->ctx, &qp_attr_ex, &efa_attr, sizeof(struct efadv_qp_init_attr));A few key differences from standard RDMA QP creation:
- QP type is
IBV_QPT_DRIVER, notIBV_QPT_RCorIBV_QPT_UD. EFA uses a custom driver-type QP that runs the SRD protocol underneath. - Extended CQ (
ibv_cq_ex) is required. EFA mandatesibv_create_cq_exwithwc_flags = IBV_WC_STANDARD_FLAGS. Using the legacyibv_create_cqwill fail. - No RC-style connection setup. Unlike RC QPs that require exchanging QPN, GID, and LID to transition through INIT → RTR → RTS with remote QP info, EFA QPs transition through these states locally without specifying a remote endpoint:
// INIT - no remote QP info needed
attr.qp_state = IBV_QPS_INIT;
attr.pkey_index = 0;
attr.port_num = PORT_NUM;
attr.qkey = QKEY;
ibv_modify_qp(qp, &attr,
IBV_QP_STATE | IBV_QP_PKEY_INDEX | IBV_QP_PORT | IBV_QP_QKEY);
// RTR - just state change, no remote info
attr.qp_state = IBV_QPS_RTR;
ibv_modify_qp(qp, &attr, IBV_QP_STATE);
// RTS - set RNR retry, no remote info
attr.qp_state = IBV_QPS_RTS;
attr.rnr_retry = 3;
ibv_modify_qp(qp, &attr, IBV_QP_STATE | IBV_QP_SQ_PSN | IBV_QP_RNR_RETRY);This is a major simplification over RC-based RDMA NICs, where you must exchange QPNs and GIDs out-of-band and set up each QP to point at its remote peer.
EFA Address Handling
Since EFA QPs are connectionless (like UDP), you need to specify the destination for each work request using an Address Handle (AH). This is the mechanism that tells the EFA NIC where to send each packet:
struct ibv_ah_attr ah_attr = {0};
ah_attr.port_num = PORT_NUM;
ah_attr.is_global = 1;
ah_attr.grh.dgid = remote_gid; // destination GID from out-of-band exchange
struct ibv_ah* ah = ibv_create_ah(rdma_ctl->pd, &ah_attr);When posting a work request, you attach the AH along with the remote QPN:
ibv_wr_set_ud_addr(qpx, ah, remote_qpn, QKEY);This connectionless model has an important implication: a single EFA QP can send to multiple remote EFA NICs. You just create different AHs for different destinations and specify the appropriate one on each WR. This is fundamentally different from RC (Reliable Connection) QPs, where each QP is bound to exactly one remote QP. The connectionless design reduces resource consumption when communicating with many peers, which is a common scenario in MoE expert-parallel workloads where each GPU talks to all other GPUs.
Of course, you still need an out-of-band mechanism (e.g., TCP sockets, as shown in our example code) to exchange QPN, GID, rkey, and remote buffer address before you can start RDMA operations.
EFA Write and Write-with-IMM
Since EFAv2 (available on p5 instances and later), EFA supports RDMA write and RDMA write with immediate data operations. These are the workhorse operations for GPU communication in NCCL and DeepEP. EFA uses the extended verbs APIs to post writes:
auto* qpx = ibv_qp_to_qp_ex(rdma_ctl->qp);
ibv_wr_start(qpx);
qpx->wr_id = 1;
qpx->wr_flags = IBV_SEND_SIGNALED;
// RDMA write with immediate data (0x1 as the imm value)
ibv_wr_rdma_write_imm(qpx, remote_rkey, remote_addr, 0x1);
struct ibv_sge sge = {
(uintptr_t)local_buf, MSG_SIZE, local_mr->lkey
};
ibv_wr_set_sge_list(qpx, 1, &sge);
ibv_wr_set_ud_addr(qpx, ah, remote_qpn, QKEY);
ibv_wr_complete(qpx);A few important notes:
ibv_wr_rdma_write_immwrites data to a remote buffer and delivers a 32-bit immediate value to the receiver’s completion queue. The receiver must have posted a receive WR to consume the immediate data. Without a posted receive, the sender will hang waiting for the RNR (Receiver Not Ready) retry to succeed.ibv_wr_rdma_write(without imm) does a pure one-sided write. The receiver does not see any completion; only the sender gets a write completion.- Both operations support zero-length writes: you can send just the immediate value without any payload by setting
sge.length = 0. This is particularly useful for signaling (e.g., notifying the receiver that prior writes have completed).
On the receiver side, polling the CQ for write-with-imm completions works with the standard ibv_poll_cq:
struct ibv_wc wc;
int n = ibv_poll_cq(cq, 1, &wc);
if (n > 0 && wc.status == IBV_WC_SUCCESS) {
if (wc.opcode == IBV_WC_RECV_RDMA_WITH_IMM) {
uint32_t imm = ntohl(wc.imm_data);
// process immediate data...
}
}EFA also supports the extended CQ polling API (ibv_start_poll / ibv_next_poll / ibv_end_poll) if you prefer that interface.
Other EFA Operations
EFA supports RDMA read and send/recv, but these operations are less commonly used for GPU communication and have more constraints:
- RDMA read works on recent EFA versions but is generally less efficient than write-based communication for GPU workloads where you want the sender to push data.
- Send/recv on some earlier EFA firmware versions only supports messages up to a single MTU size (~8-9 KB). This makes it unsuitable for large data transfers without application-level chunking.
For GPU communication workloads, we recommend sticking with RDMA write and write-with-imm as the primary operations.
EFA Ordering and Atomics
This is where EFA programming gets both interesting and challenging. EFA’s SRD multi-path transport introduces two constraints that do not exist on traditional single-path RDMA NICs:
- No ordering guarantees between any two operations from the same QP.
- No native RDMA atomics (and definitely no atomics over GPU memory).
The Ordering Problem
On a traditional RC RDMA NIC (e.g., ConnectX-7), if node A posts write1 then write2 to the same QP, the completions are guaranteed to appear in order on both the sender’s and receiver’s CQs. On EFA, because SRD sprays packets across multiple network paths, the later write may arrive first. Specifically:
- Receiver side: Node B might see
write2’s completion arrive beforewrite1’s in its CQ. - Sender side: Node A might see
write2’s send completion beforewrite1’s.
This is a fundamental consequence of multi-path transport: different paths have different latencies, and packets sent later on a shorter path can overtake packets sent earlier on a longer path.
The Atomics Problem
Many GPU communication patterns rely on write + atomic sequences: node A performs write1, write2, write3 to transfer data, then issues an atomic add to node B’s counter. Node B’s GPU kernel spins on this atomic counter to determine when prior writes have arrived. On NVIDIA NICs, the NIC hardware guarantees that the atomic is delivered after all preceding writes, and the atomic operation itself is performed by the NIC on the remote memory.
EFA supports neither native RDMA atomics nor ordering, so how should we do? The answer is we can emulate both in software!
Software Atomics via Write-with-IMM
The key idea is to emulate atomics using empty write-with-imm (zero payload, only the 32-bit immediate value) plus a CPU proxy thread on the receiver side. An empty write-with-imm means “this is an atomic operation”; a non-empty write-with-imm means “this is a real data write.” The approach:
- Allocate a
cudaHostAllocbuffer (pinned CPU memory accessible by both GPU and CPU) to serve as the atomic buffer. - When the sender wants to perform a remote “atomic add”, it issues an empty write-with-imm carrying the atomic metadata (offset, value) in the 32-bit immediate.
- The receiver-side CPU proxy polls its CQ, sees a zero-length write-with-imm, recognizes it as an atomic, and performs a CPU atomic on the shared buffer:
// Receiver-side CPU proxy: upon receiving an empty write-with-imm
counter->fetch_add(value, std::memory_order_release);- The GPU kernel on the receiver side polls this counter using acquire-semantic loads:
// GPU kernel: spin-wait on the counter in cudaHostAlloc memory
while (ld_acquire_sys_global(counter_ptr) == 0)
; // spinBecause the atomic buffer is cudaHostAlloc memory, CPU writes with memory_order_release are visible to the GPU’s acquire loads, providing the necessary CPU-GPU memory ordering.
Receiver-Side Sequence-Based Reordering
To guarantee write-then-atomic ordering despite EFA’s out-of-order delivery, we need to involves some sequencing semantics. This requires two parts: 1) use write-with-imm for any RDMA write, 2) embed a monotonic sequence number into the immediate data of every write-with-imm. Now, both data writes and atomic writes carry a sequence number, so the receiver can tell which operations have arrived and which are still in flight. More importantly, the receiver proxy can delay update the atomic counter until all proceeding writes have arrived.
The receiver-side CPU proxy implements a simple reordering protocol:
def handle_completion(cqe):
imm = read_imm_data(cqe)
seq = get_seq(imm)
if is_empty(cqe): # Empty write-with-imm => emulated atomic
if all_writes_received_up_to(seq):
commit_atomic_to_gpu_memory(imm)
else:
pending_atomics.append(imm)
else: # Non-empty write-with-imm => real data write
mark_write_received(seq)
try_fire_pending_atomics()
def try_fire_pending_atomics():
"""Check if any pending atomics can now commit."""
for pending in pending_atomics:
if all_writes_received_up_to(pending.seq):
commit_atomic_to_gpu_memory(pending)
pending_atomics.remove(pending)This is essentially the same idea as TCP reordering: attach a sequence number to every operation and let the receiver reassemble the correct order. The reordering window is bounded by the maximum number of in-flight operations per channel, so the bookkeeping is lightweight.
Why Not Sender-Side Reordering?
An alternative approach is sender-side ordering: the sender holds the atomic operation until it polls the send completion of all preceding writes. However, this adds latency because the sender must wait at least half an RTT for the transport-layer ACK of the last write before issuing the atomic. On EFA with 15-25 us RTTs, this is significant.
The receiver-driven approach pipelines the atomic with the writes: the sender fires the atomic immediately after the writes without waiting, and the receiver reorders as needed. This results in measurably lower end-to-end latency:
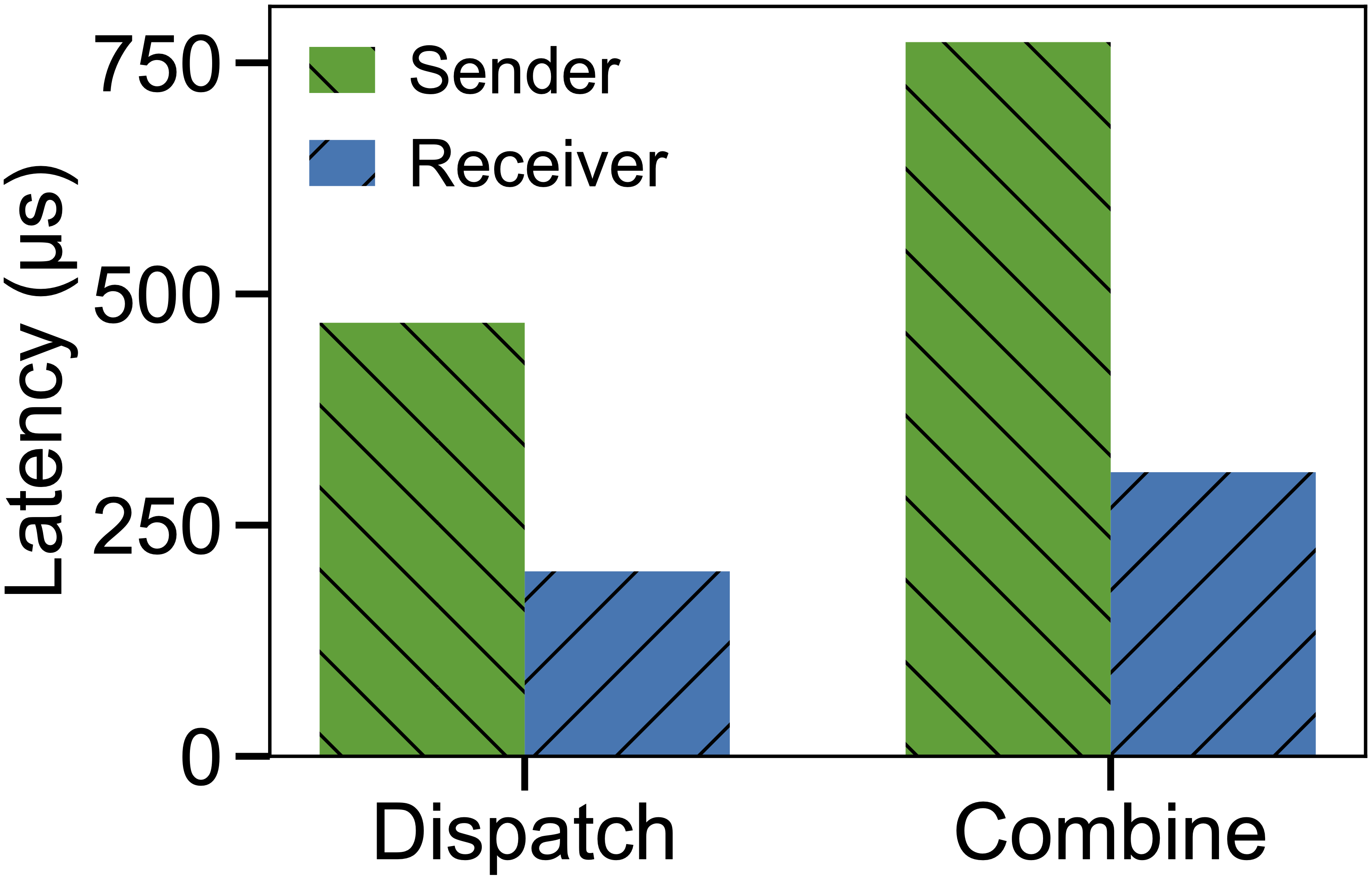
Latency comparison between sender-side ordering (hold atomic until all write completions) vs. receiver-side reordering approach.
EFA Performance Characteristics
Based on our experience with multiple RDMA NIC vendors including NVIDIA, Broadcom, AMD, Intel, we find EFA performance is excellent for large messages (dozens of MB and above), on par with NVIDIA ConnectX and Broadcom Thor-2 NICs. In our testing across p5en (EFAv3, 16x 200Gb/s) and p6 (EFAv4, 8x 400Gb/s) instances, EFA NICs are clearly saturating the network bandwidth for large messages with NCCL.
More importantly, EFA is remarkably reliable. In our extensive testing, we have never encountered a transport retry counter exceeded error (CQE error 12) on EFA, while we frequently see it on other RDMA vendors under high load. We attribute this directly to EFA’s SRD multi-path transport: by dynamically spreading traffic across many paths, SRD avoids the congestion buildup that plagues single-path transports, especially under incast patterns common in GPU communication workloads. Other vendors rely on a combination of adaptive routing and PFC inside the network fabric, which is fundamentally harder to get right.
Small-Message Latency
EFA design does sacrifice small-message latency. We typically observe 15-25 us RTTs on EFA, compared to ~10 us on NVIDIA InfiniBand/RoCE networks. This is likely because of the advanced multi-path processing, whose overhead is amortized over large transfers but visible at small message sizes.
For workloads with many small messages (e.g., fine-grained GPU-initiated communication sending ~7 KB per message), this latency gap means the EFA’s per-message processing rate becomes a bottleneck. To mitigate this issue, UCCL-EP has introduced per-expert batching to batch small messages into larger RDMA writes before sending, which we found improved latency by up to 18% on p5en.
Tradeoffs Summary
| Aspect | EFA (SRD) | Traditional RDMA (RC) |
|---|---|---|
| Large-message throughput | Excellent (on par) | Excellent |
| Small-message latency | 15-25 us | ~10 us |
| Reliability under load | Very high (no PFC needed) | Depends on PFC + AR tuning |
| Native RDMA atomics | No | Yes |
| In-order delivery | No | Yes (per QP) |
| Connection model | Connectionless (like UDP) | Connection-oriented |
| Multi-destination per QP | Yes (via AH) | No (1:1 QP binding) |
The lack of atomics and ordering is a real constraint that hinders many advanced communication libraries (e.g., DeepEP) from running on EFA directly. Fortunately, UCCL fully addresses these constraints with the software atomics and receiver-side reordering techniques described above, enabling advanced GPU communication on AWS instances. Check out our UCCL project for more details.