Everything You Want to Know about KV Cache Transfer Engine
By: UCCL Team — Aug 13, 2025
KV cache transfer is becoming more and more important for modern disaggregated LLM serving with prefill and decode separation. It typically transfers the KV cache generated by the prefill GPU node to the separate decode GPU node via fast RDMA networks. Therefore, the KV cache transferring speed directly impacts the end-to-end request latency.
There have been quite a few KV cache transfer engines in the open-source world, including NCCL/RCCL (for AMD), Nvidia NIXL, and Mooncake TE (Transfer Engine), but nearly no benchmarks on their performance. This blog serves for this purpose—benchmarking and analyzing the performance of various KV transfer engines, so you can decide how to choose.
We also want to introduce the UCCL KV transfer engine called UCCL P2P. As we will show soon, it provides an easy-to-use collective APIs like NCCL/RCCL, but provides much better performance than NCCL/RCCL without burning any SMs for the scenario of peer-to-peer KV cache transfer. So in total, this blog will compare the performance of the following four transfer engines: NCCL/RCCL, NIXL, Mooncake TE, and UCCL P2P.
Transfer engine designs
NCCL/RCCL were mainly used for collective communication, like allreduce in LLM training and inference workloads. NCCL and RCCL have almost the same design and codebase, except that they were built for Nvidia and AMD GPUs, respectively. It provides flexible send/recv P2P transfer APIs that can be used for KV cache transfer. NCCL/RCCL always requires launching a GPU kernel even when doing send/recv P2P transfers. Therefore, it will consume some GPU SM resources during the transfer process. These GPU SMs are mainly used for data copy and reduce operations in complex collectives, but should be unnecessary during P2P transfer.
NIXL was created by Nvidia Dynamo distributed LLM inference framework, as its KV transfer solution. It has a modular design with a bunch of transfer backends, including file systems, POSIX sockets, and RDMA networks. It has several RDMA network backends: one is based on a famous communication library from the HPC community, called UCX; another is exactly the Mooncake TE that we will benchmark soon. One thing worth noting is that UCX supports AMD GPUs. NIXL provides vastly different APIs from the NCCL/RCCL, with read/write operations between KV cache exporter nodes and importer nodes. A node needs to export some metadata for its KV cache using an out-of-band network, such as a TCP socket or an ETCD service endpoint, so that the other nodes can read from or write to the KV data. It does not consume GPU SM resources, as the KV cache is directly transferred in a GPU-Direct RDMA manner.
Mooncake TE is a component of the serving platform for Kimi from Moonshot AI. It also has different APIs other than NCCL/RCCL, very similar to NIXL style of read/write. It leverages GPU-Direct RDMA to directly transfer the KV cache without consuming GPU SM resources. It has a cool feature of automatically detecting the NIC and GPU affinity from PCIe topology, so that applications do not need to specify which NIC to use for each GPU. However, based on our testing, it has not supported AMD GPUs so far.
UCCL P2P is our recently developed KV cache transfer engine that features SM-freeness, a light-weight codebase, and easy-to-use interfaces. It is based on UCCL’s multi-path RDMA transport engine, provides both read/write and collective send/recv APIs without burning any GPU SMs, and auto-detect GPU-NIC topology. Its collective APIs avoid the need for an explicit out-of-band network for metadata dispersing. You can check our collective APIs here.
Benchmarking setup
Our benchmark testbed consists of two AMD GPU nodes, each with 8 MI300X GPUs and 8 Broadcom Thor-2 400Gbps NICs (or 50GB/s). We use the first GPU of each node with its most-affinitive NIC to benchmark P2P transfers. We use a wide range of message sizes, ranging from a few KB to dozens of MB, to reflect the possible KV cache size in practice. We measure the end-to-end latency of each single message transfer and calculate its achieved bandwidth. For the Mooncake engine, since it does not support AMD GPUs, we use host DRAM for KV cache transfer. We have double checked that for NIXL and UCCL P2P, using host DRAM won’t change their performance for our targeted single-direction two-GPU transfer scenario.
For Mooncake, we use its official C++ benchmark transfer_engine_bench.cpp; for others, we use their Python APIs to implement simple KV cache transfer benchmarks.
Benchmarking results
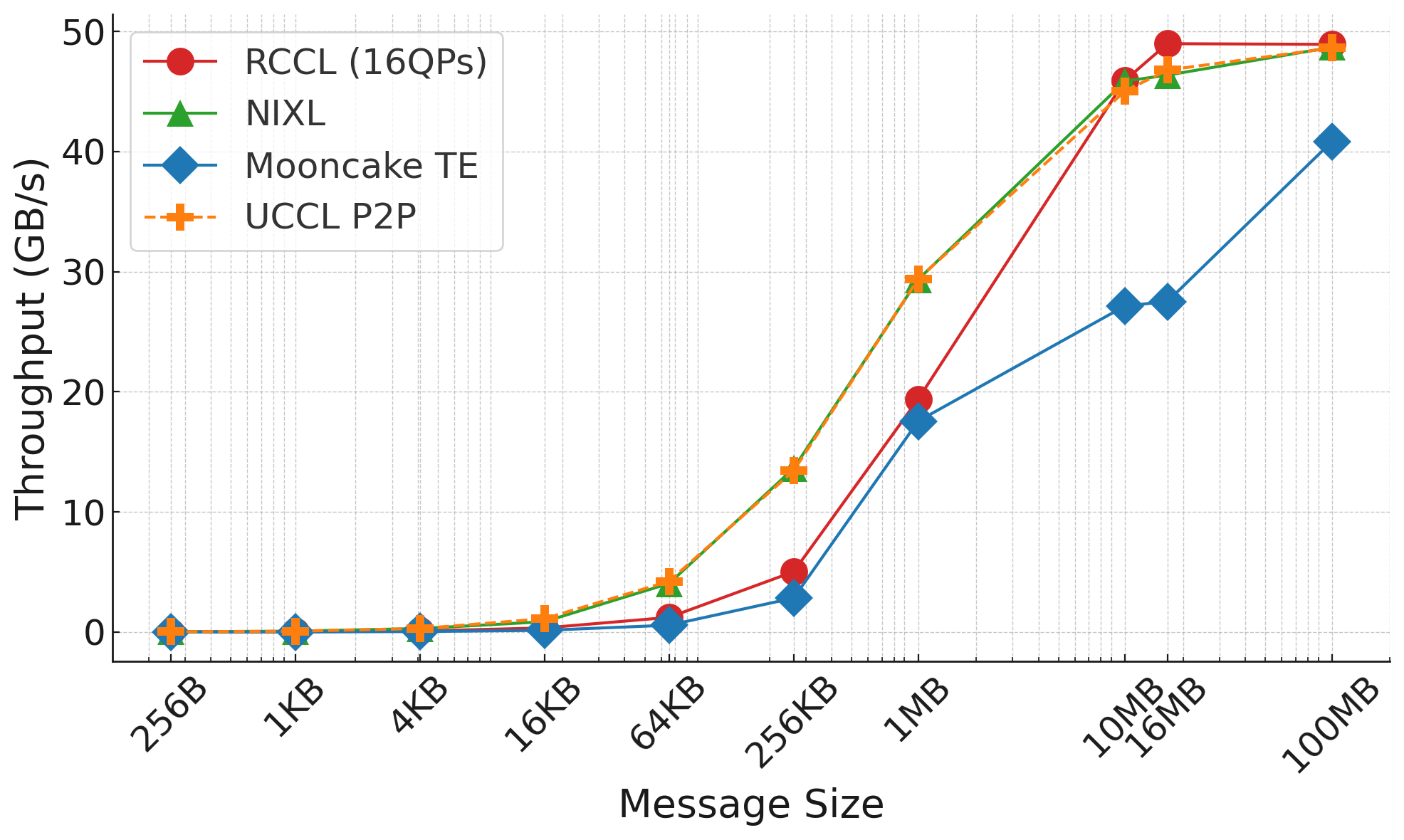 Figure 1: Throughput comparison of different KV cache transfer engines.
Figure 1: Throughput comparison of different KV cache transfer engines.
The above figure shows the benchmarking results with NIXL and UCCL P2P achieving the best performance for almost all message sizes. NCCL/RCCL performs roughly 30-50% slower than NIXL and UCCL P2P for 256KB and 1MB message sizes typically seen in KV cache transfer scenarios. But NCCL/RCCL’s performance reaches or even surpasses NIXL and UCCL P2P after 10MB. We think this might be because of NCCL/RCCL-internal smart message chunking mechanisms.
Surprisingly, we find Mooncake TE performs the worst, not able to saturate 50GB/s network link even at 100MB. We failed to find a architecture-level issues for it, but can only attribute it to the potentially buggy implementation. One thing to note is that we find by tuning the number of task submission threads in the Mooncake transfer_engine_bench.cpp, it can achieve 50GB/s line rate, but this is in contrast to other engine’s ability of reaching line rate with only one task submission thread.
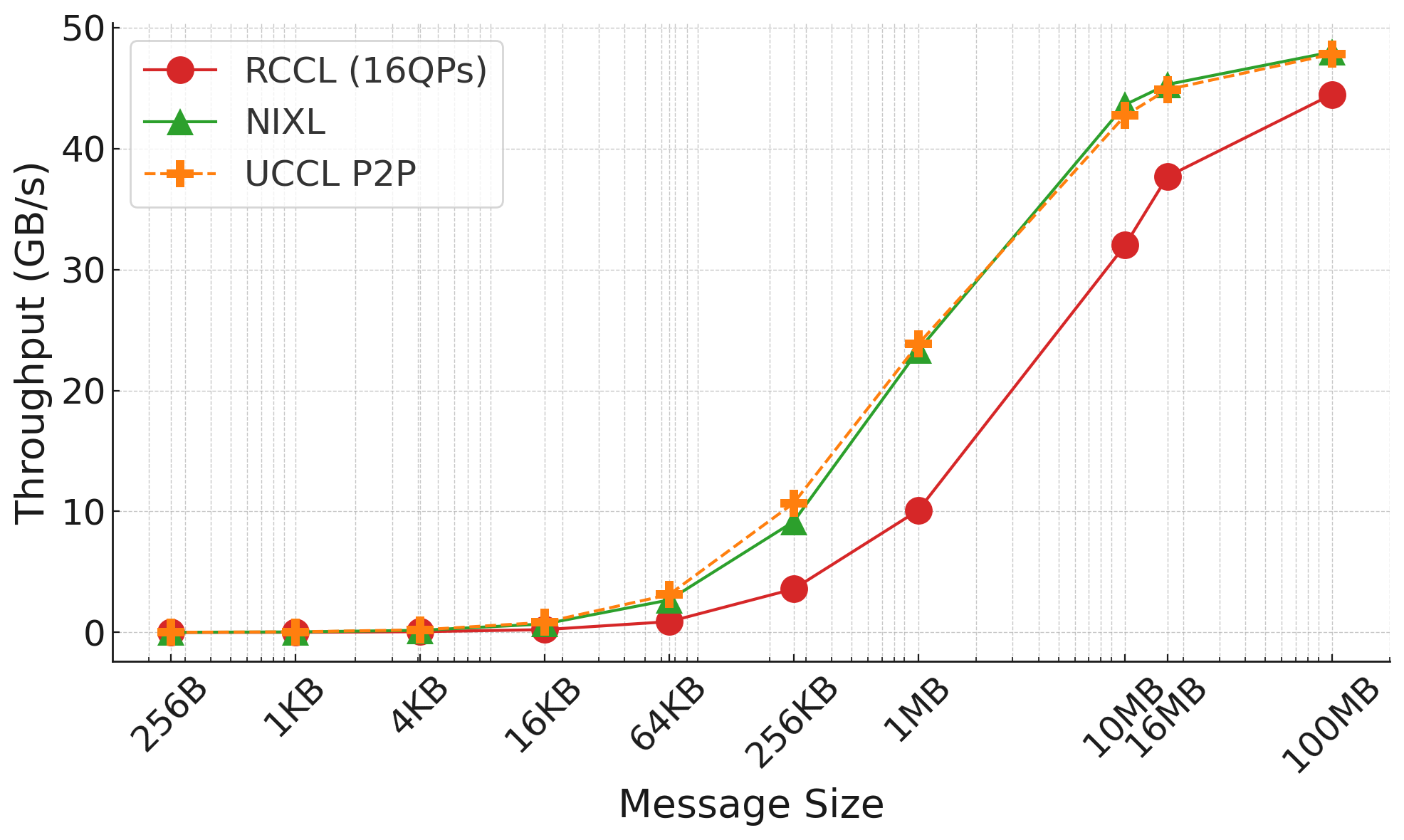 Figure 1: Throughput comparison for dual-direction transfers.
Figure 1: Throughput comparison for dual-direction transfers.
We also perform another interesting benchmark that does KV transfer between two GPUs in dual directions to stress test the engine transfer performance. The results are shown above, where we find that NCCL/RCCL starts to see SM being the transfer bottlenecks. UCCL P2P performs slightly better than NIXL at the 256KB message size.
Comparison summary
| Throughput | API | SM-free | AMD support | Auto-detect topo | |
|---|---|---|---|---|---|
| NCCL/RCCL | Medium | Collective | No | Yes | Yes |
| NIXL | High | Read/Write | Yes | Yes | No |
| Mooncake TE | Low | Read/Write | Yes | No | Yes |
| UCCL P2P | High | Collective + Read/Write | Yes | Yes | Yes |
Last words on UCCL P2P
UCCL P2P is rapidly evolving, and we would love to hear your feedback and contributions. Our next goal is to extend our send/recv collective to more types of collectives without burning any GPU SM resources, to accelerate distributed video generation and understanding scenarios. So talk to us and checkout our GitHub repository (https://github.com/uccl-project/uccl) if you are interested in how UCCL P2P can help accelerate these emerging scenarios. Stay tuned!