Previewing UCCL-EP: Flexible and Efficient Expert Parallelism for Cloud and Beyond
By: Ziming Mao (UC Berkeley), Yang Zhou (UC Davis), Yihan Zhang (UC Davis), Chihan Cui (UW-Madison), Zhongjie Chen (Tsinghua), Zhiying Xu (AWS), and other UCCL-EP contributors
Date: Oct 27, 2025
GPU-driven communication (e.g., DeepEP) is the key to efficient and large-scale EP, but it cannot run on heterogeneous platforms in the public cloud due to tight coupling between GPU and NIC. UCCL-EP has exactly the same interface and functionality as DeepEP, but allows you to run GPU-driven communication for MoE models on public clouds, such as AWS, with superior performance to the state-of-the-art. Our ultimate goal with UCCL-EP is to democratize EP for heterogeneous GPUs and NIC vendors, including AMD GPUs, Broadcom NICs, AMD Pensando NICs, and more. UCCL-EP open-source: uccl-project/uccl/ep
Expert Parallelism (EP)
Expert Parallelism (EP) is widely used in large-scale Mixture-of-Experts (MoE) models, where different subsets of the model’s “experts” are placed on different GPUs across multiple nodes. During inference or training, each input token is routed—based on a learned gating function—to one or a few selected experts.
This selective routing requires frequent dispatch (sending token embeddings to the correct expert GPUs) and combine (gathering expert outputs back to the sender ranks, followed by a weighted sum) operations across the network. These data exchanges are typically performed using Remote Direct Memory Access (RDMA) over high-speed interconnects such as InfiniBand or RoCE.
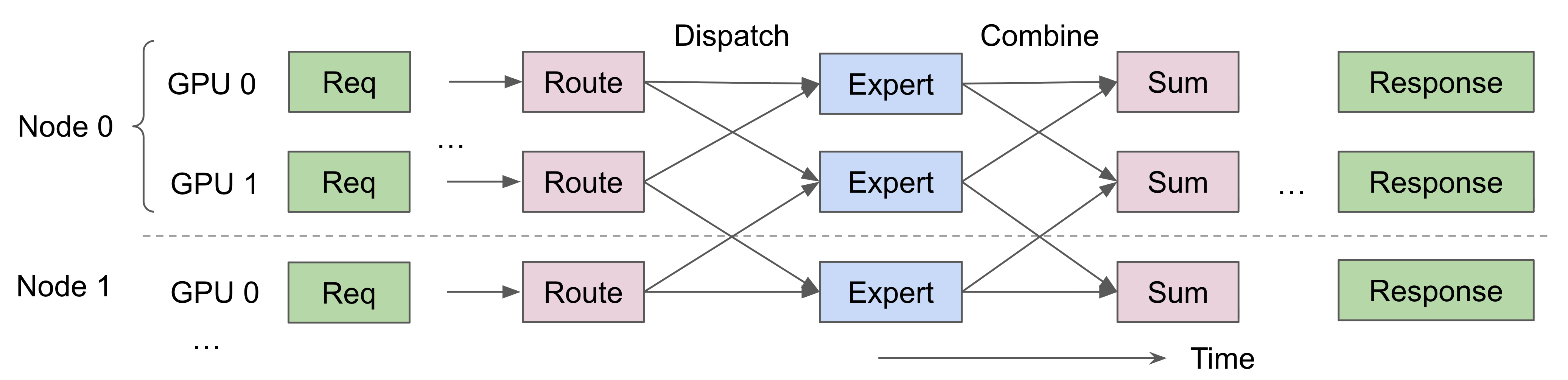 Figure 1: Expert parallelism communication involves frequent dispatch and combine operations across multiple GPUs and nodes.
Figure 1: Expert parallelism communication involves frequent dispatch and combine operations across multiple GPUs and nodes.
Unlike traditional data or tensor parallelism, where communication involves large contiguous tensors (on the order of megabytes or gigabytes), EP communication is highly fine-grained. Each dispatch or combine operation often involves small message sizes—for example, 7 KB (inference) to 256 KB (training) in models like DeepSeek V3. Such small message sizes pose a challenge for general-purpose collective communication libraries like NCCL, which are optimized for high-throughput transfers of large payloads (e.g., in all-reduce or all-gather operations). When messages are this small, the per-transfer latency and synchronization overhead dominate, leading to poor utilization of network bandwidth. Consequently, EP systems often require custom, low-latency communication runtimes that can overlap computation and communication efficiently and handle a large number of concurrent small-message operations.
One popular library for EP is DeepEP, which leverages NVIDIA-specific NVSHMEM/IBGDA techniques to let NVIDIA GPUs directly issue RDMA operations to NVIDIA NICs for small-message efficiency. IBGDA essentially runs the NIC driver functions inside the GPU SM cores, so that the GPUs can talk to NICs, bypassing the CPU. The GPU can thus enqueue RDMA writes, reads, or atomic operations straight to the NIC’s doorbell registers. However, while DeepEP has high performance, it suffers from two limitations caused by tight coupling between GPUs and NICs.
Limitations of Tightly Coupling NIC and GPU
Lack of Portability
DeepEP is tightly coupled with the NVIDIA software and hardware ecosystem. It depends on NVIDIA GPUs, NVIDIA NICs, and their proprietary networking stack (e.g., NVSHMEM, GPUDirect, and IBGDA). As a result, DeepEP can only run on NVIDIA-controlled platforms where these components are co-designed and supported.
This design significantly limits portability. For instance, DeepEP cannot run on AWS cloud instances, which use Elastic Fabric Adapter (EFA) RDMA NICs instead of NVIDIA hardware. Similar incompatibilities arise on other public clouds and data center environments that deploy non-NVIDIA RDMA solutions, such as Broadcom Thor NICs, Google Cloud Falcon NICs, and AMD Pensando NICs. The same restriction applies to GPU vendors—DeepEP’s reliance on NVIDIA-specific APIs and device driver interfaces makes it difficult, if not impossible, to run on AMD or Intel GPUs, even when comparable RDMA-capable networking hardware is present.
This lack of cross-vendor portability increasingly limits deployment flexibility as modern AI clusters become more heterogeneous across GPU architectures and networking fabrics.
Lack of Control and Visibility
By moving NIC driver logic into GPU threads, DeepEP sacrifices fine-grained control and observability over the communication process. In traditional CPU-driven RDMA systems, the host manages flow control, queue depth, completion notifications, and load balancing across multiple network queues. These mechanisms are essential for ensuring low tail latency, congestion avoidance, and recovery under high network pressure.
In the IBGDA model, however, GPUs issue RDMA operations directly without the CPU’s coordination. In other words, GPU threads are “blindly” issuing one-sided operation. This makes it difficult to monitor or regulate traffic. For example, the GPU may post many outstanding RDMA writes without awareness of NIC queue utilization, leading to congestion or high tail latency. Detecting transfer completion, measuring transfer latency, or handling network backpressure is also not possible in GPU or DeepEP, as IBGDA or NVSHMEM does not expose relevant interfaces.
UCCL-EP
UCCL-EP directly tackles these challenges and proposes a flexible yet efficient EP solution for the public cloud and heterogeneous device vendors, including GPU and NICs. UCCL-EP preserves the same APIs as DeepEP, supporting both the low latency (for decode) and normal mode (for prefill and training).
The core insight of UCCL-EP is that efficient expert-parallel communication, while benefiting from GPU initiation, does not require GPUs to directly control the NIC. Instead, UCCL-EP restores a clean separation of concerns between GPU and CPU:
- GPUs retain their massive parallelism for data-intensive tasks — such as token packing, expert combination, NVL forwarding, and local RDMA buffering, and efficient overlap with the background RDMA communication. GPU still initiates communication.
- CPUs handle the control-intensive aspects of networking — including queue management, flow control, completion handling, and load balancing — through a lightweight, multi-threaded CPU proxy.
Essentially, instead of having GPUs post RDMA operations directly to the NIC (as in NVIDIA’s IBGDA model), each GPU forwards lightweight control commands—such as “write this token to peer X”—to the CPU through an efficient shared memory channel. A pool of multi-threaded CPU proxies then interprets these commands and issues the actual RDMA verbs to the NIC on the GPU’s behalf. GPU still initiates communication, thereby overlapping with on-GPU data copying and computation, while the CPU manages the complexity and control decisions of RDMA communication.
We note that UCCL-EP’s approach shares similarity with NVSHMEM’s IBRC solution that uses CPU proxies as well, but differs significantly from them by leveraging multiple CPU proxy threads for performance, and supporting a wide range of vendors for portability.
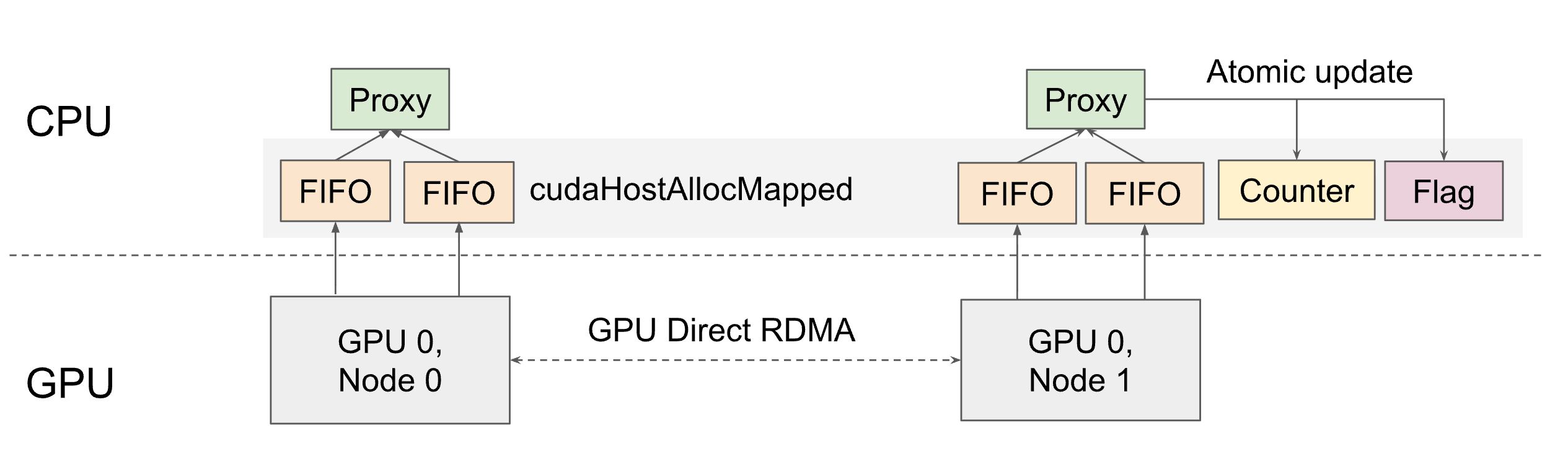 Figure 2: RDMA commands initiated by the GPU are handed off to multiple CPU proxy threads.
Figure 2: RDMA commands initiated by the GPU are handed off to multiple CPU proxy threads.
This design exploits a key observation: every RDMA NIC already exposes a standardized, vendor-neutral interface via the libibverbs library, maintained by the Linux-RDMA community. By having GPUs forward RDMA requests to CPU threads over PCIe, while communication is still initiated by GPUs, UCCL-EP can issue network operations on behalf of GPUs using the same verbs API that any NIC driver supports.
The second observation underlying UCCL-EP’s design is that CPU–GPU communication latency is not the dominant bottleneck. Modern interconnects such as PCIe Gen5, NVLink, and C2C (chip-to-chip) links offer microsecond-scale latency and tens to hundreds of GB/s bandwidth between CPUs and GPUs. This means that forwarding a control command from the GPU to the CPU is extremely fast—especially compared to the end-to-end latency of an RDMA operation that traverses the network.
Moreover, each control command in expert parallelism typically represents a batched data movement involving multiple tokens. Therefore, the amortized cost of sending a command descriptor over PCIe is negligible relative to the data transferred.
Designing an Efficient CPU-GPU Communication Channel
A central challenge in UCCL-EP is building an efficient forwarding channel between GPUs and CPUs that can sustain tens of millions of RDMA requests per second without becoming a bottleneck. UCCL-EP implements this channel as a lock-free FIFO queue shared between GPU producers and CPU consumers. Each GPU enqueues lightweight RDMA transfer descriptors into the queue, while multiple CPU threads dequeue and execute them.
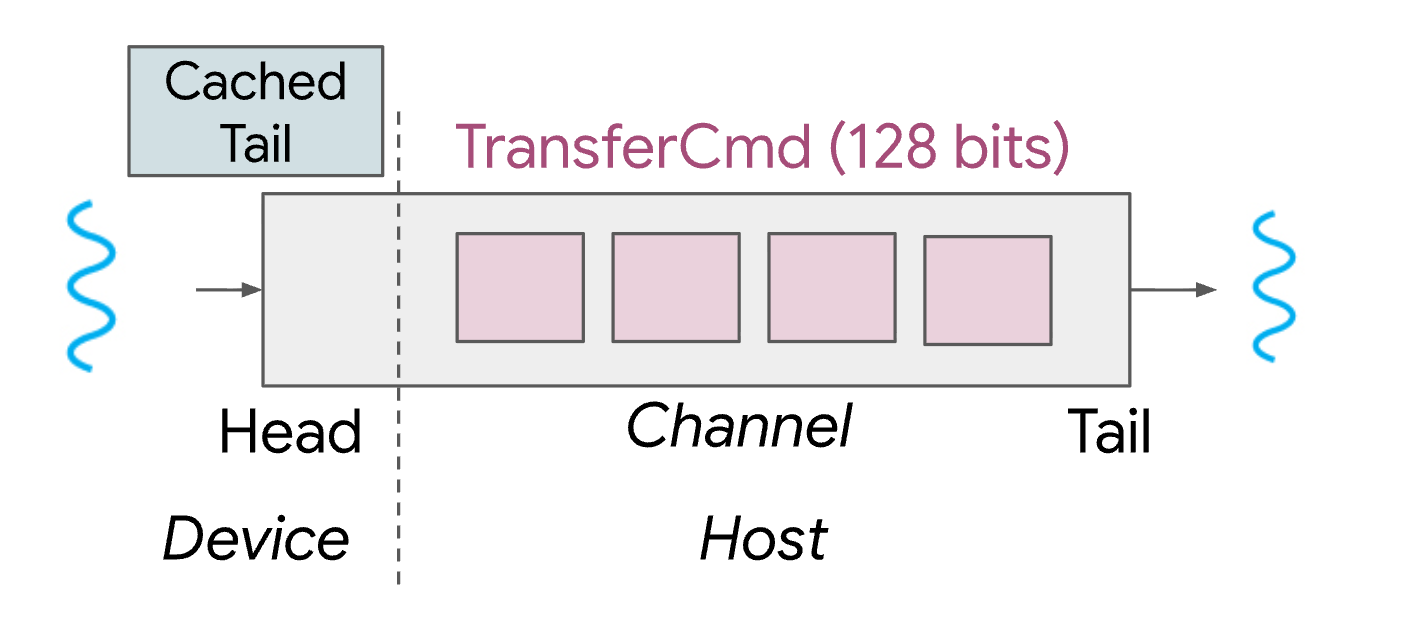 Figure 3: UCCL-EP employs multiple channels per GPU; The tail is read by CPU thread and allocated on host, the head is read and updated by GPU thread and allocated on device. It further caches the tail value on GPU for faster access. Each TransferCmd is small, occupying only 128 bits.
Figure 3: UCCL-EP employs multiple channels per GPU; The tail is read by CPU thread and allocated on host, the head is read and updated by GPU thread and allocated on device. It further caches the tail value on GPU for faster access. Each TransferCmd is small, occupying only 128 bits.
UCCL-EP employs multiple channels per GPU; each channel has its own dedicated RDMA Queue Pair (QP). This design allows each GPU to achieve over 50 million RDMA operations per second with modest latency overhead (as shown in UCCL PR #454), where the NIC’s intrinsic latency and network delay—not the CPU–GPU channel—becomes the dominant cost.
Working with Various GPU-NIC Vendors
Different NIC vendors introduce additional system-level challenges due to variations in transport protocols and hardware capabilities. For instance, AWS EFA NICs use the Scalable Reliable Datagram (SRD) protocol, which employs advanced multi-pathing to mitigate congestion at scale. While this design improves throughput and reliability, it does not provide the strict in-order delivery guarantee within a single SRD Queue Pair (QP). This becomes problematic for DeepEP-style communication, which relies on ordered RDMA writes followed by atomic operations to notify remote GPUs that writes are delivered to assigned locations in the RDMA transport buffer.
To address this, UCCL-EP leverages its CPU-side flexibility to enforce software-level message ordering. Each RDMA write carries immediate data encoding a per-RDMA-channel sequence number, which the receiver uses to reorder out-of-sequence messages before committing them to GPU memory. Importantly, these only apply to control messages (e.g. atomics) and not the data payload.
Furthermore, In DeepEP’s NVIDIA-specific IBGDA path, GPUs rely on hardware RDMA atomics to signal remote completion. However, some NIC providers (e.g. EFA) does not natively support RDMA atomics, which poses a correctness challenge: the receiver must still know when a payload has been fully written before it can proceed to read or combine it.
To emulate this behavior, UCCL-EP implements software-level atomics using regular RDMA writes and immediate data. The sender writes the payload first, then issues a small RDMA write carrying an immediate value that acts as an atomic message (e.g., the new counter value or flag). On the receiver side, the CPU proxy updates a local completion counter — effectively reproducing the behavior hardware atomics.
A surprising benefit of this approach is that atomic can piggyback on existing write operation (as realized in one RDMA operation), whereas in DeepEP, it takes two operations (write + atomic). The fundamental reason is that UCCL-EP adopts a two-sided communication model, whereas the original DeepEP is one-sided due to GPU needing to directly talking to NIC.
To enable UCCL EP work with diverse GPU vendors, we have taken the first step in eliminating nvshmem dependencies, which is important for portability as well as other features (e.g. elastic scaling). We also observed interestingly, removing nvshmem dependency can sometimes lead to performance improvements, which we suspect to be due to the internal overhead of the nvshmem library.
Performance
On EFA, we observe UCCL-EP significantly outperforms other baselines as we increase the number of tokens in dispatch and combine. We used unmodified Perplexity MoE Kernels and ran on H200 with EFA NICs. For the NVSHMEM and Torch baselines, we wrote an efficient packing and unpacking kernel, and relied on their respective AlltoAll APIs to distribute packed tokens to destination ranks in a single contiguous transfer.
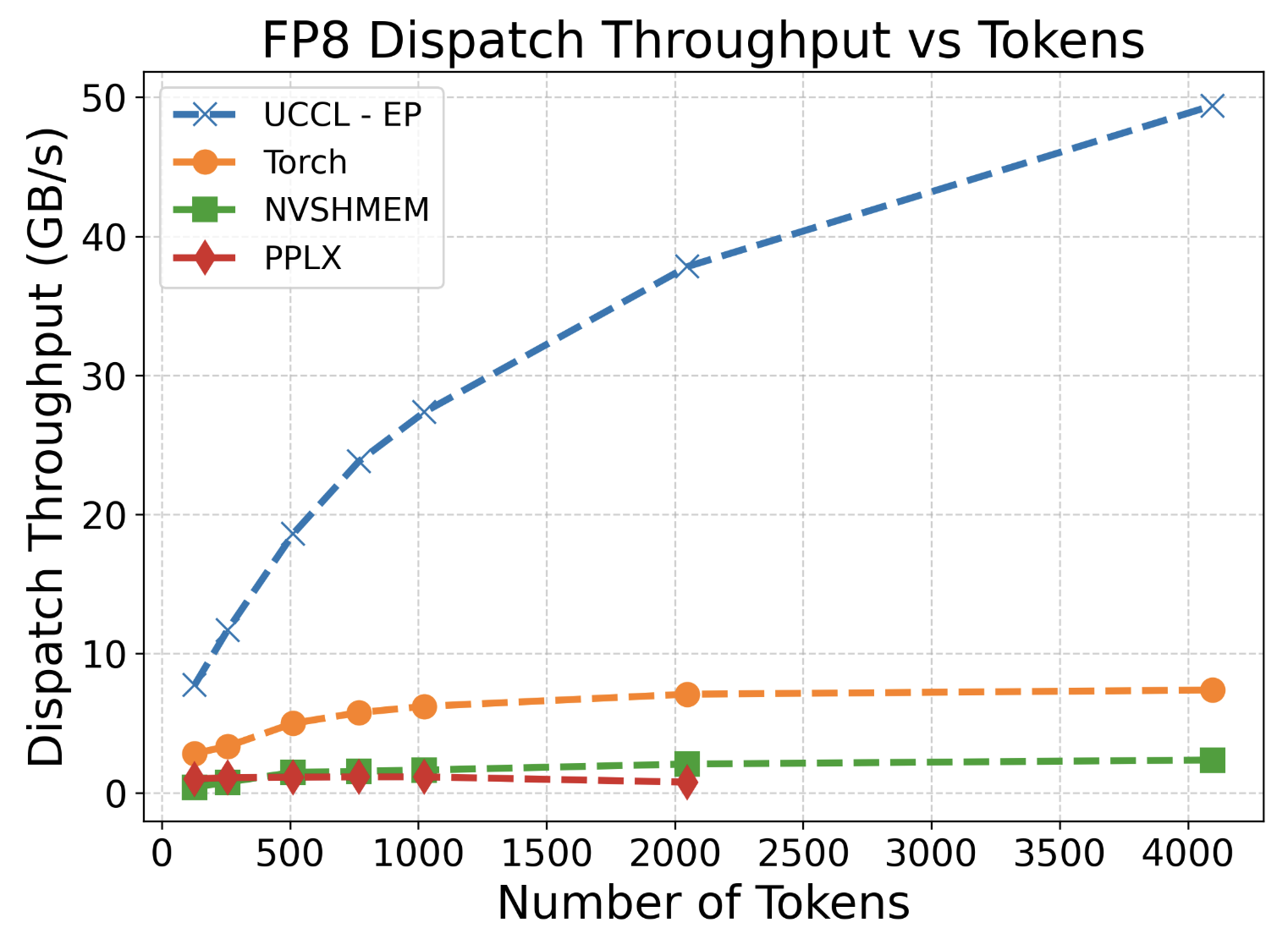 Figure 4: On 2 nodes, H200 + EFA (400 Gbps). PPLX errored out for 4096 tokens.
Figure 4: On 2 nodes, H200 + EFA (400 Gbps). PPLX errored out for 4096 tokens.
We also tested normal kernels on H200 (8× GPUs per node) with each node connected to an EFA 400 Gb/s RDMA network card. We follow the DeepSeek-V3 pretraining configuration (4096 tokens per batch, 7168 hidden, top-4 groups, top-8 experts, FP8 dispatch and BF16 combine).
| Type | Dispatch FP8 #EP | Bottleneck bandwidth | Combine BF16 #EP | Bottleneck bandwidth |
|---|---|---|---|---|
| Intranode | 8 | 320 GB/s (NVLink) | 8 | 319 GB/s (NVLink) |
| Internode | 16 | 50 GB/s (RDMA) | 16 | 18 GB/s (RDMA) |
| Internode | 24 | 53 GB/s (RDMA) | 24 | 26 GB/s (RDMA) |
| Internode | 32 | 54 GB/s (RDMA) | 32 | 43 GB/s (RDMA) |
Across different EP sizes, the dispatch bandwidth exceeds 50 GB/s, while the combine bandwidth stabilizes around 40 GB/s. The slightly lower combine bandwidth reflects the additional overhead of the combine operation (e.g., weighted sum across experts), and that combine inherently sends fewer RDMA messages compared to dispatch (e.g. with TopK=8) due to per-node local aggregation, therefore the RDMA pipeline is not as full. A similar issue was noted in the original DeepEP repo (Issue #82), where congestion is pointed out as a problem. We are still investigating the relatively lower combine throughput compared to dispatch at EP=16.
On a small testbed with GH200, we observe that UCCL-EP even outperforms the original DeepEP. We are surprised by the results, and hypothesize two reasons: the fast NVLink-C2C interconnect with CPU-GPU cache coherence on GH200 makes CPU-GPU communication almost for “free”; and the internal overhead of nvshmem. That said, we would like to verify the finding on larger testbeds.
Additional results, benchmark code, and instructions can be found here.
UCCL EP Roadmap
UCCL-EP is still in active development, and we expect new results in the coming months. We plan to release a formal blog on application-level performance as well as performance on AMD GPUs and other NIC vendors. Our current roadmap includes:
- Further improving UCCL-EP performance on EFA
- Finishing porting to AMD GPUs and Broadcom NICs (PR #457)
- Advanced flow control and congestion management in the CPU
- Integrating into vLLM and SGLang—contributions are much welcomed!
Acknowledgements
We thank AWS, Lambda Labs for providing us with the main testbeds. We especially thank Kaichao You, Lequn Chen, Zhen Huang, Zhenyu Gu, Costin Raiciu, Scott Shenker, Ion Stoica for their discussions and feedbacks. This research is supported by gifts from Accenture, AMD, Anyscale, AWS, Broadcom, Cisco, Google, IBM, Intel, Intesa Sanpaolo, Lambda, Lightspeed, Mibura, Microsoft, NVIDIA, Samsung SDS, and SAP.