UCCL-EP: Portable Expert-Parallel Communication — Full Results
By: Ziming Mao (UC Berkeley), ChonLam Lao (Harvard), Yang Zhou (UC Davis), Yihan Zhang (UC Davis), Chihan Cui (UW-Madison), Zhongjie Chen (Tsinghua), Zhiying Xu (AWS), and other UCCL-EP contributors
Date: Dec 20, 2025
We present UCCL-EP, a portable expert-parallel communication library that achieves state-of-the-art performance across heterogeneous GPU and NIC hardware. UCCL-EP outperforms the best existing EP solution by up to 2.3x for dispatch and combine on AWS EFA. For end-to-end applications, UCCL-EP improves Megatron-LM training throughput by up to 45% over RCCL on 128 AMD GPUs andspeeds up SGLang inference throughput by up to 40% over NCCL over 32 H200 GPUs.
Paper: arxiv.org/pdf/2512.19849 | Code: uccl-project/uccl/ep
Recap: Why UCCL-EP?
In our previous blog post, we introduced UCCL-EP and the key challenge it addresses: state-of-the-art EP communication systems like DeepEP achieve high performance through GPU-initiated token-level RDMA, but are tightly coupled to the NVIDIA GPU + NVIDIA NIC ecosystem (via IBGDA). This tight coupling prevents running on public clouds like AWS (which use EFA NICs), on AMD GPUs, or on alternative NIC vendors like Broadcom.
UCCL-EP solves this with a clean separation of concerns:
- GPUs retain fine-grained token-level communication initiation for maximal overlap with computation.
- CPUs handle the control-intensive networking aspects — queue management, flow control, ordering enforcement — through a lightweight, multi-threaded proxy.
This architecture reduces the porting effort from O(m x n) (left figure, for m GPU vendors and n NIC vendors) down to O(m) (right figure), as the CPU proxy can use the libibverbs API that most RDMA NICs support. In fact, UCCL-EP provides drop-in support for vLLM, SGLang, and Megatron-LM, making it easy to adopt without modifying application or framework code.
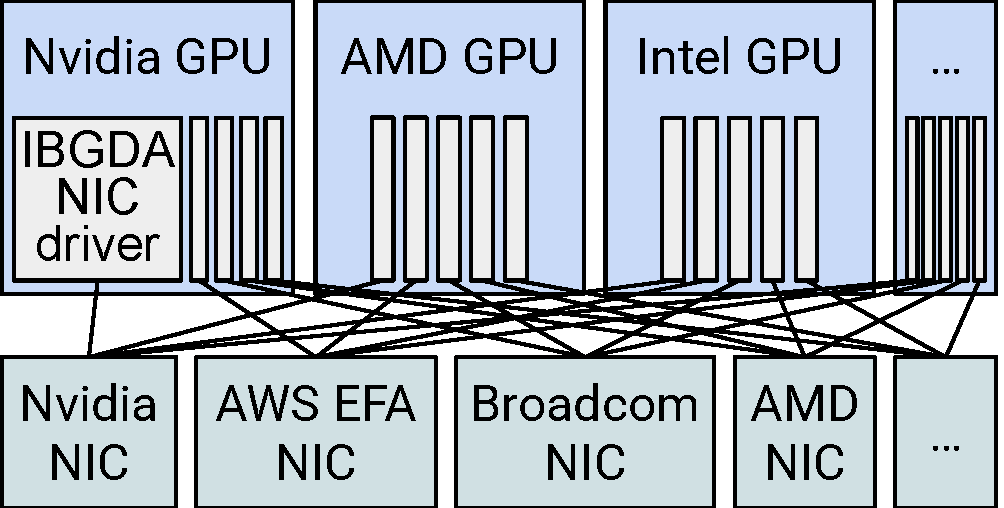
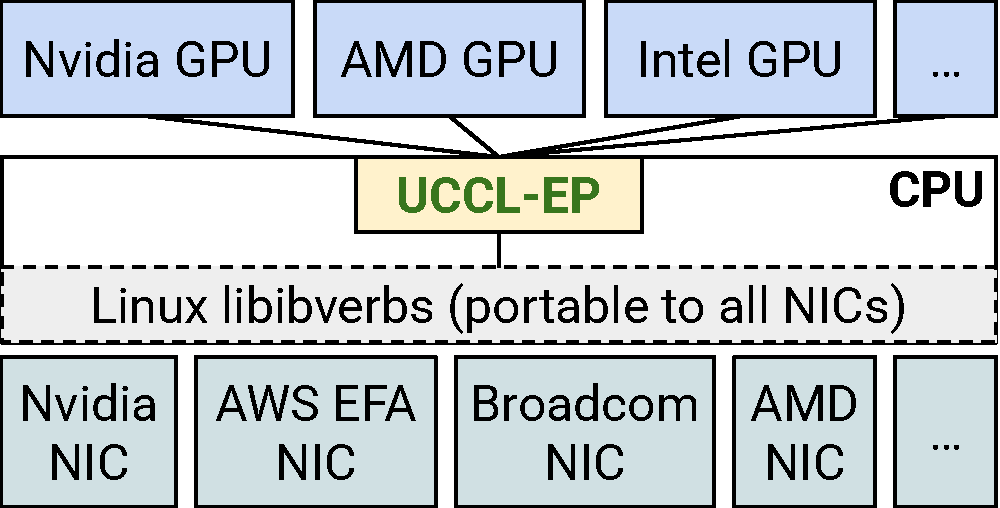
Left: IBGDA-style GPU-initiated communication requires O(m x n) porting effort across GPU and NIC vendors. Right: UCCL-EP reduces this to O(m) by using the CPU as a portable intermediary via libibverbs.
UCCL-EP architecture is shown in the figure below. GPUs delegate token-routing commands to multi-threaded CPU proxies via lock-free FIFO channels. CPU proxies issue GPUDirect RDMA on behalf of GPUs, while managing ordering, flow control, and completion handling.
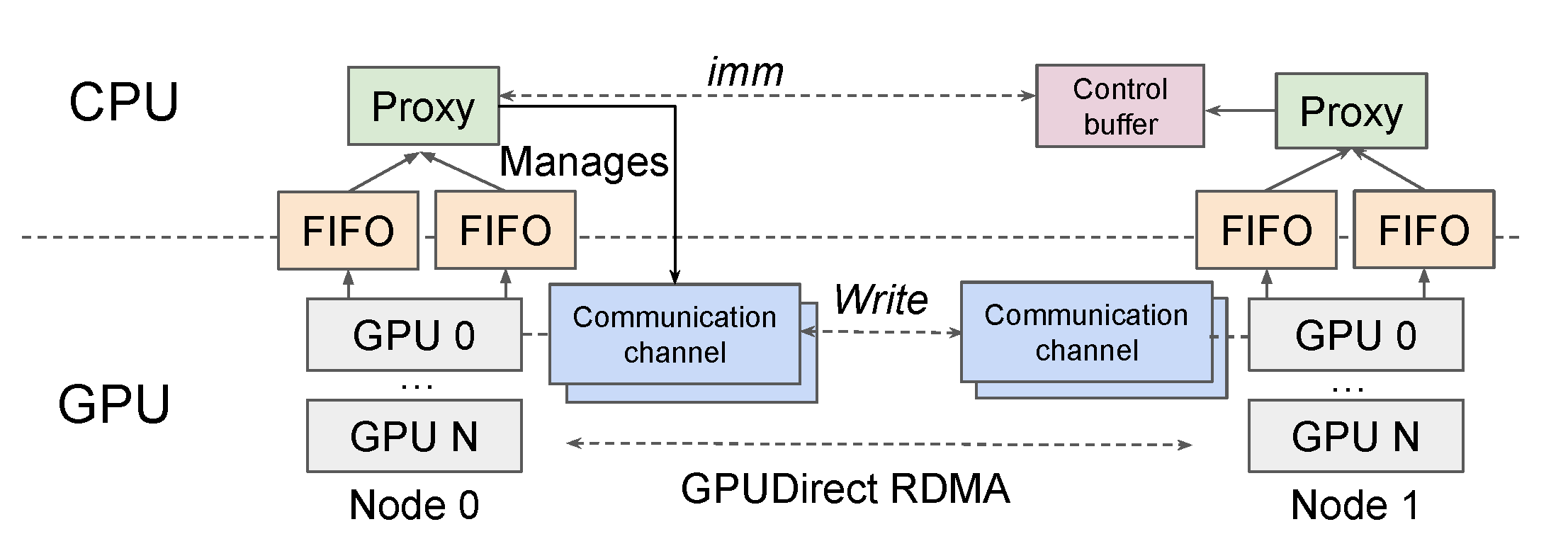 UCCL-EP architecture.
UCCL-EP architecture.
We discuss two key techniques in UCCL-EP (please refer to the paper for more details):
CPU Proxy with Lock-Free FIFO Channels. UCCL-EP uses a 128-bit TransferCmd descriptor that GPU threads enqueue into shared, lock-free FIFO channels. CPU proxy threads dequeue these commands and issue the corresponding RDMA operations. Each GPU uses multiple FIFO channels, each mapped to a dedicated RDMA Queue Pair (QP).
Immediate-Data-Based Ordering for Heterogeneous NICs. Different NICs provide different delivery guarantees. For example, AWS EFA uses the Scalable Reliable Datagram (SRD) protocol with multi-pathing, which does not guarantee in-order delivery within a single QP. UCCL-EP embeds per-channel sequence numbers into RDMA immediate data, allowing the receiver-side CPU proxy to reorder out-of-sequence control messages before committing them to GPU memory. This approach also enables software-level atomics — piggybacking completion notifications on regular RDMA writes — which is both more portable (no hardware atomic support required) and more efficient (one RDMA operation instead of two for write + atomic).
CPU Proxy Throughput Is Not the Bottleneck
We measure the FIFO channel latency and compare it against the end-to-end RDMA latency on EFA and Broadcom NICs. The FIFO channel sustains over 8 million operations per second, with average latency of ~3 us and P99 under 8 us — an order of magnitude lower than the RDMA network latency (which ranges from 20–50+ us on EFA). This confirms that the CPU-GPU channel is not the bottleneck, and the additional proxy latency is amortized across the much larger network transfer time.
Evaluation Testbeds
We have since evaluated UCCL-EP on a diverse set of platforms spanning NVIDIA and AMD GPUs with EFA, InfiniBand, and Broadcom NICs.
| Name | Servers | GPU | NIC | CPU | Cloud |
|---|---|---|---|---|---|
| NV_EFAv3 | 4 | NVIDIA H200 x8 | AWS EFAv3 200G x16 | 192 cores | AWS (p5en) |
| NV_EFAv4 | 4 | NVIDIA B200 x8 | AWS EFAv4 400G x8 | 192 cores | AWS (p6-b200) |
| NV_IB | 4 | NVIDIA H100 x8 | ConnectX-7 400G x8 | 128 cores | Nebius |
| NV_GH200 | 2 | NVIDIA GH200 x1 | ConnectX-7 200G x1 | 72 cores | Lambda |
| AMD_CX7 | 4-16 | AMD MI300X x8 | ConnectX-7 400G x8 | 128 cores | OCI |
| AMD_BRC | 4 | AMD MI300X x8 | Broadcom Thor-2 400G x8 | 128 cores | Vultr |
| AMD_AINIC | 4 | AMD MI355X x8 | Pollara AI NIC IB x8 | 128 cores | AMD |
Baselines: NCCL/RCCL, DeepEP (NVIDIA-only), Perplexity Kernels (PPLX), and CPU-assisted IBGDA. UCCL-EP uses 4 CPU proxy threads per GPU.
Microbenchmark Results
On AWS EFA (NVIDIA GPUs)
H200 + EFA (p5en)
On p5en instances (8x H200, 16x 200 Gb/s EFA), we measure EP32 dispatch and combine latency while varying the number of tokens. UCCL-EP uses the minimum of high-throughput (HT) and low-latency (LL) mode latency, while PPLX operates in a single mode.
At small batch sizes (128 tokens), PPLX achieves lower latency because UCCL-EP (extending DeepEP) issues messages at 7 KB token granularity, whereas PPLX packs tokens into larger messages. However, as the token count increases, UCCL-EP quickly overtakes PPLX — delivering 2.3x lower dispatch latency and 1.1–1.5x lower combine latency for medium and large batches.
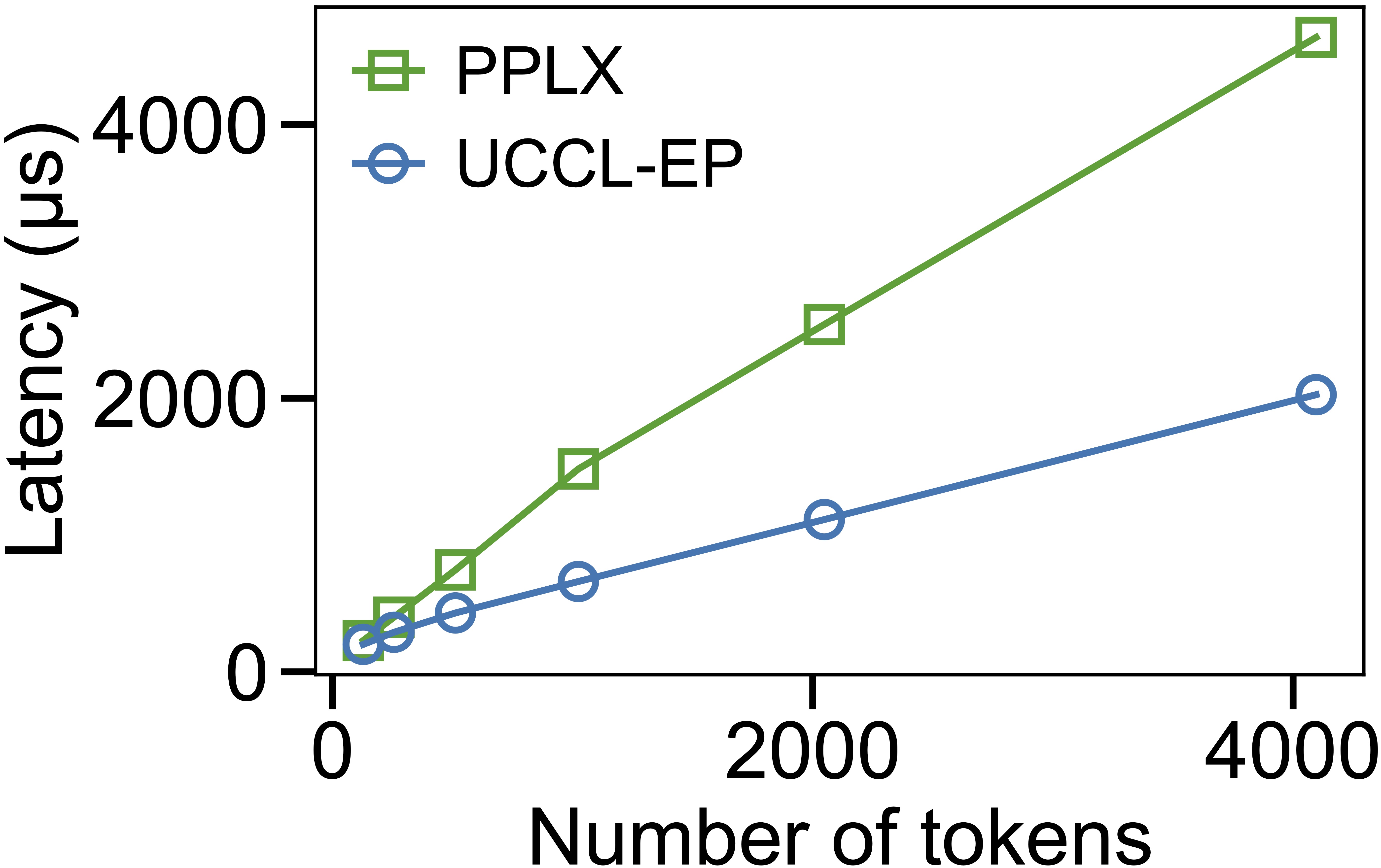
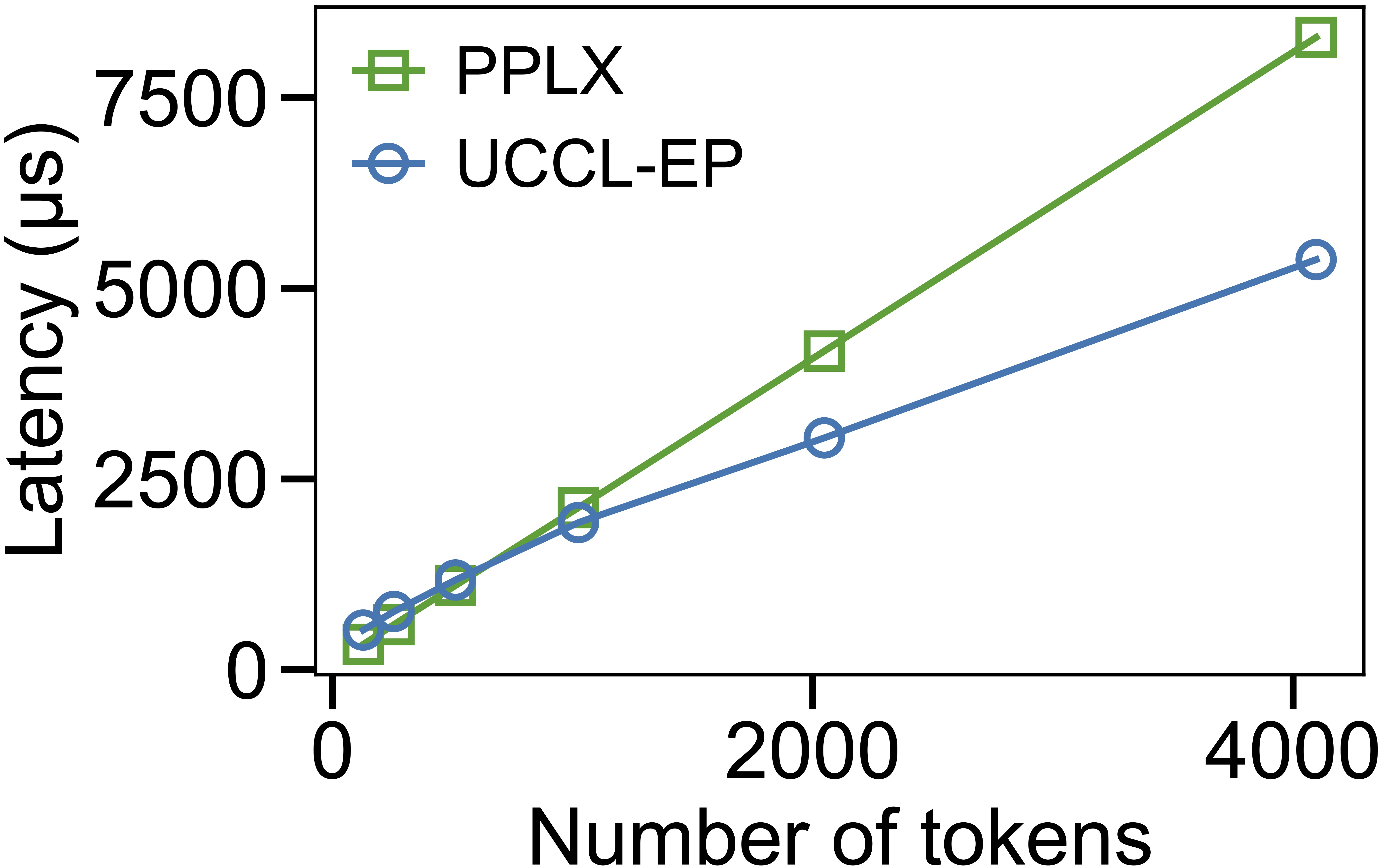
EP32 dispatch (left) and combine (right) latency vs. number of tokens on p5en (H200 + EFA 400 Gbps).
We present more results in the table below.
Normal Mode Bandwidth (EFA)
Following the DeepSeek-V3 pretraining configuration (4096 tokens, 7168 hidden, top-4 groups, top-8 experts, FP8 dispatch / BF16 combine):
| Platform | Type | #EP | Dispatch BW & Latency | Combine BW & Latency |
|---|---|---|---|---|
| p5en (H200) | Intranode | 8 | 320 GB/s (NVLink), 500 us | 319 GB/s (NVLink), 973 us |
| p5en (H200) | Internode | 16 | 50 GB/s (RDMA), 1196 us | 18 GB/s (RDMA), 6379 us |
| p5en (H200) | Internode | 24 | 53 GB/s (RDMA), 1633 us | 26 GB/s (RDMA), 6365 us |
| p5en (H200) | Internode | 32 | 54 GB/s (RDMA), 2022 us | 43 GB/s (RDMA), 4899 us |
| p6 (B200) | Intranode | 8 | 280 GB/s (NVLink), 571 us | 426 GB/s (NVLink), 727 us |
| p6 (B200) | Internode | 16 | 53 GB/s (RDMA), 1141 us | 60 GB/s (RDMA), 1965 us |
| p6 (B200) | Internode | 24 | 53 GB/s (RDMA), 1637 us | 59 GB/s (RDMA), 2887 us |
| p6 (B200) | Internode | 32 | 53 GB/s (RDMA), 2072 us | 57 GB/s (RDMA), 3724 us |
Low-Latency Mode (EFA)
Following a DeepSeek-V3 inference setting (128 tokens, 7168 hidden, top-8 experts, FP8 dispatch / BF16 combine):
| Platform | #EP | Dispatch Latency | Dispatch BW | Combine Latency | Combine BW |
|---|---|---|---|---|---|
| p5en (H200) | 16 | 226 us | 36 GB/s | 293 us | 48 GB/s |
| p5en (H200) | 24 | 386 us | 20 GB/s | 580 us | 26 GB/s |
| p5en (H200) | 32 | 465 us | 16 GB/s | 694 us | 25 GB/s |
| p6 (B200) | 16 | 228 us | 33 GB/s | 318 us | 46 GB/s |
| p6 (B200) | 24 | 448 us | 17 GB/s | 566 us | 26 GB/s |
| p6 (B200) | 32 | 406 us | 19 GB/s | 617 us | 24 GB/s |
On InfiniBand (NVIDIA CX7)
On the Nebius testbed (H100 + CX7 InfiniBand), we compare UCCL-EP against both the original DeepEP and PPLX at EP32.
In LL mode, UCCL-EP incurs slightly higher latency than DeepEP and PPLX due to the CPU proxy overhead on small messages. However, in HT mode, UCCL-EP achieves latency within 5% of DeepEP for dispatch while outperforming PPLX by 2.1x (dispatch) and 1.6x (combine). This shows that UCCL-EP preserves DeepEP-level performance on throughput-oriented workloads even without IBGDA.
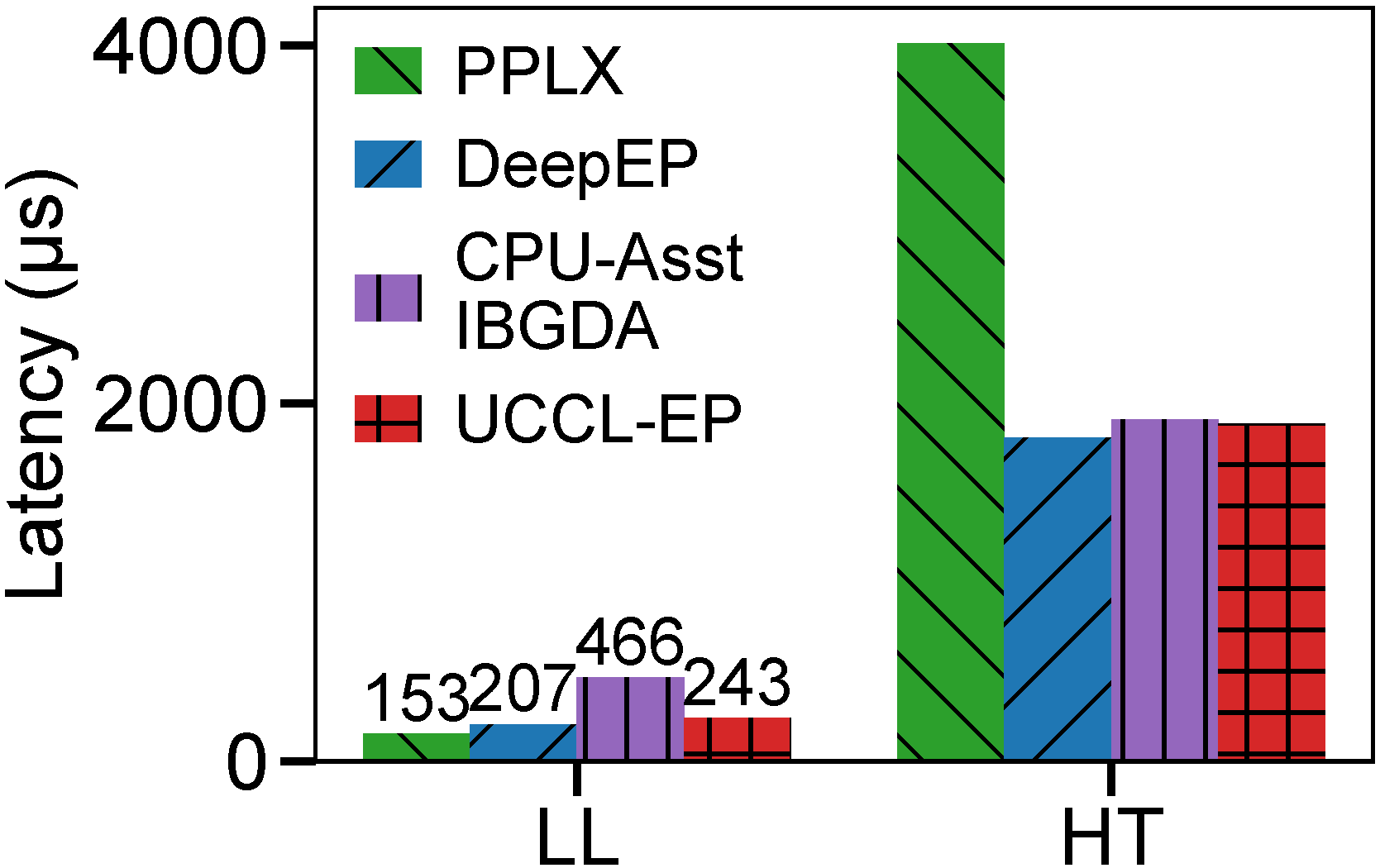
EP32 dispatch (left) and combine (right) comparison on H100 + CX7 InfiniBand. UCCL-EP matches DeepEP in HT mode and significantly outperforms PPLX.
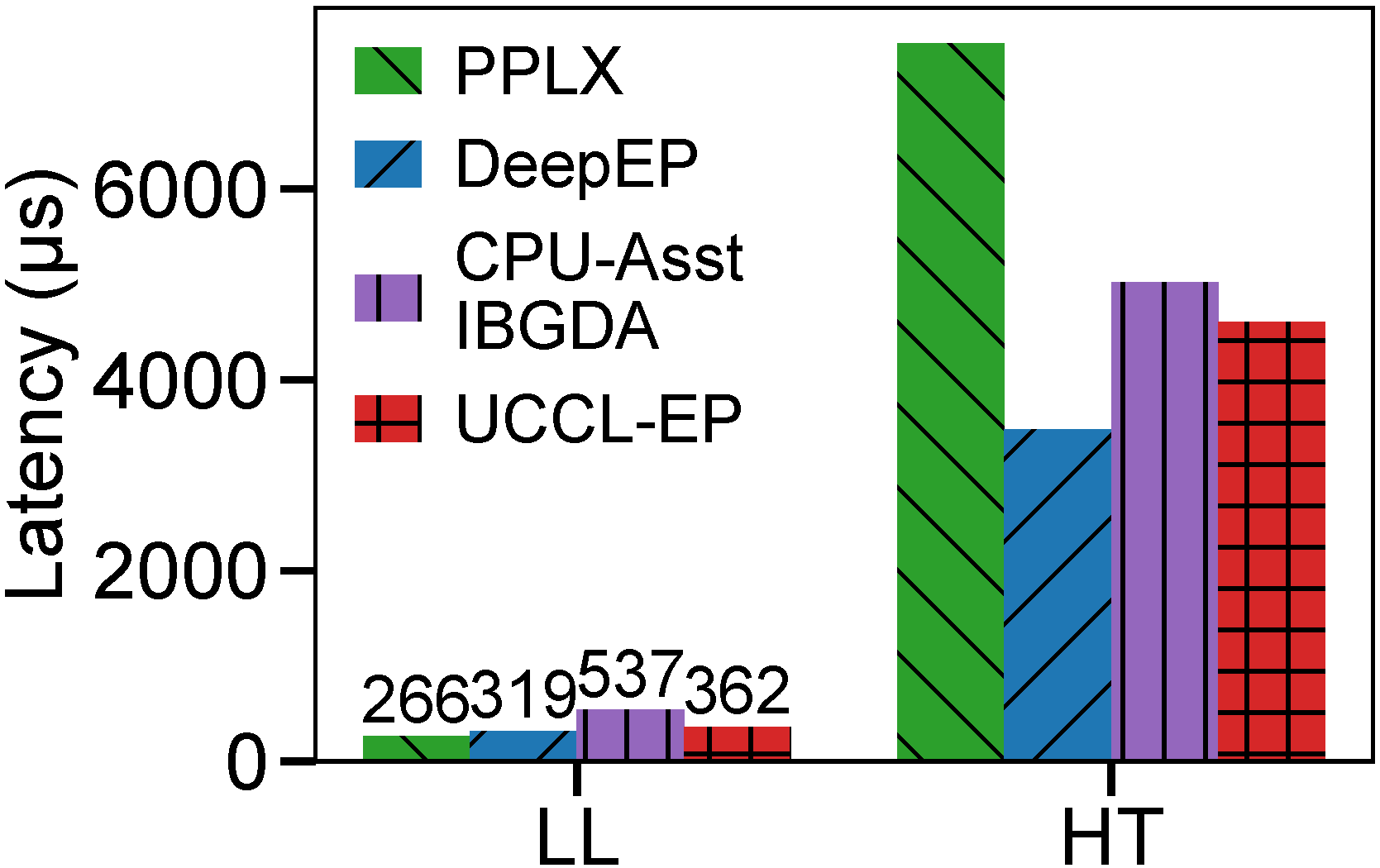
On AMD GPUs
UCCL-EP enables GPU-initiated token-level EP communication on AMD GPUs. We evaluate on MI300X with both CX7 InfiniBand (OCI) and Broadcom Thor-2 NICs (Vultr).
EP32 dispatch (left) and combine (right) on AMD MI300X with CX7 RoCE and Broadcom Thor-2 NICs.
More results across heterogeneous platforms are shown in the tables below.
Normal Mode Bandwidth (AMD)
| Platform | Type | #EP | FP8 Dispatch BW | BF16 Dispatch BW | Combine BW |
|---|---|---|---|---|---|
| MI300X + CX7 RoCE | Intranode | 8 | 260 GB/s (xGMI) | 295 GB/s (xGMI) | 304 GB/s (xGMI) |
| MI300X + CX7 RoCE | Internode | 16 | 74 GB/s (RDMA) | 82 GB/s (RDMA) | 78 GB/s (RDMA) |
| MI300X + CX7 RoCE | Internode | 32 | 60 GB/s (RDMA) | 61 GB/s (RDMA) | 60 GB/s (RDMA) |
| MI300X + CX7 RoCE | Internode | 64 | 52 GB/s (RDMA) | 53 GB/s (RDMA) | 51 GB/s (RDMA) |
| MI355X + Pollara | Intranode | 8 | 299 GB/s (xGMI) | 336 GB/s (xGMI) | 333 GB/s (xGMI) |
| MI355X + Pollara | Internode | 16 | 82 GB/s (RDMA) | 82 GB/s (RDMA) | 82 GB/s (RDMA) |
| MI355X + Pollara | Internode | 32 | 59 GB/s (RDMA) | 58 GB/s (RDMA) | 59 GB/s (RDMA) |
| MI355X + Pollara | Internode | 64 | 50 GB/s (RDMA) | 49 GB/s (RDMA) | 49 GB/s (RDMA) |
| MI300X + Broadcom | Internode | 16 | 71 GB/s (RDMA) | 81 GB/s (RDMA) | 45 GB/s (RDMA) |
| MI300X + Broadcom | Internode | 32 | 49 GB/s (RDMA) | 55 GB/s (RDMA) | 50 GB/s (RDMA) |
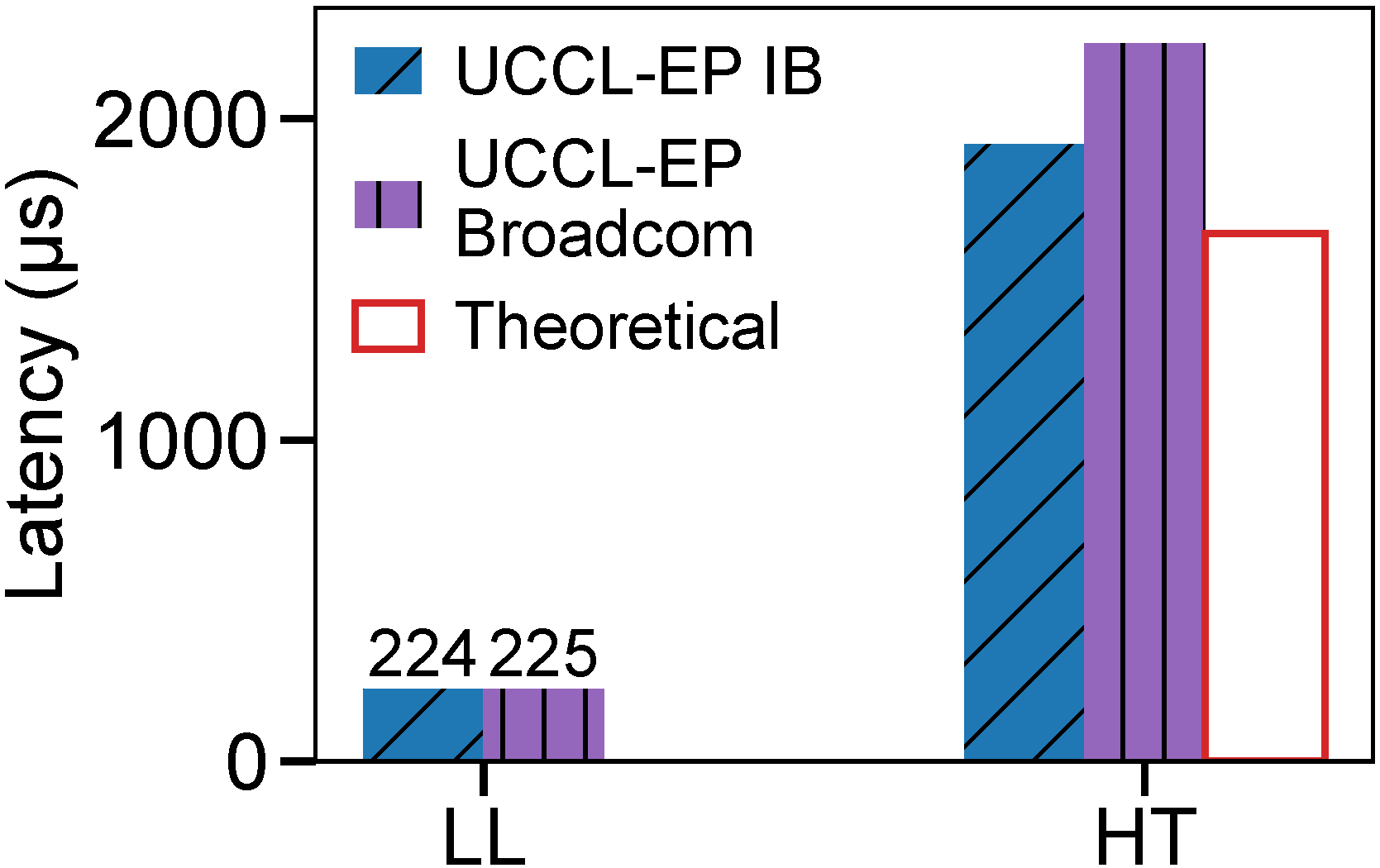
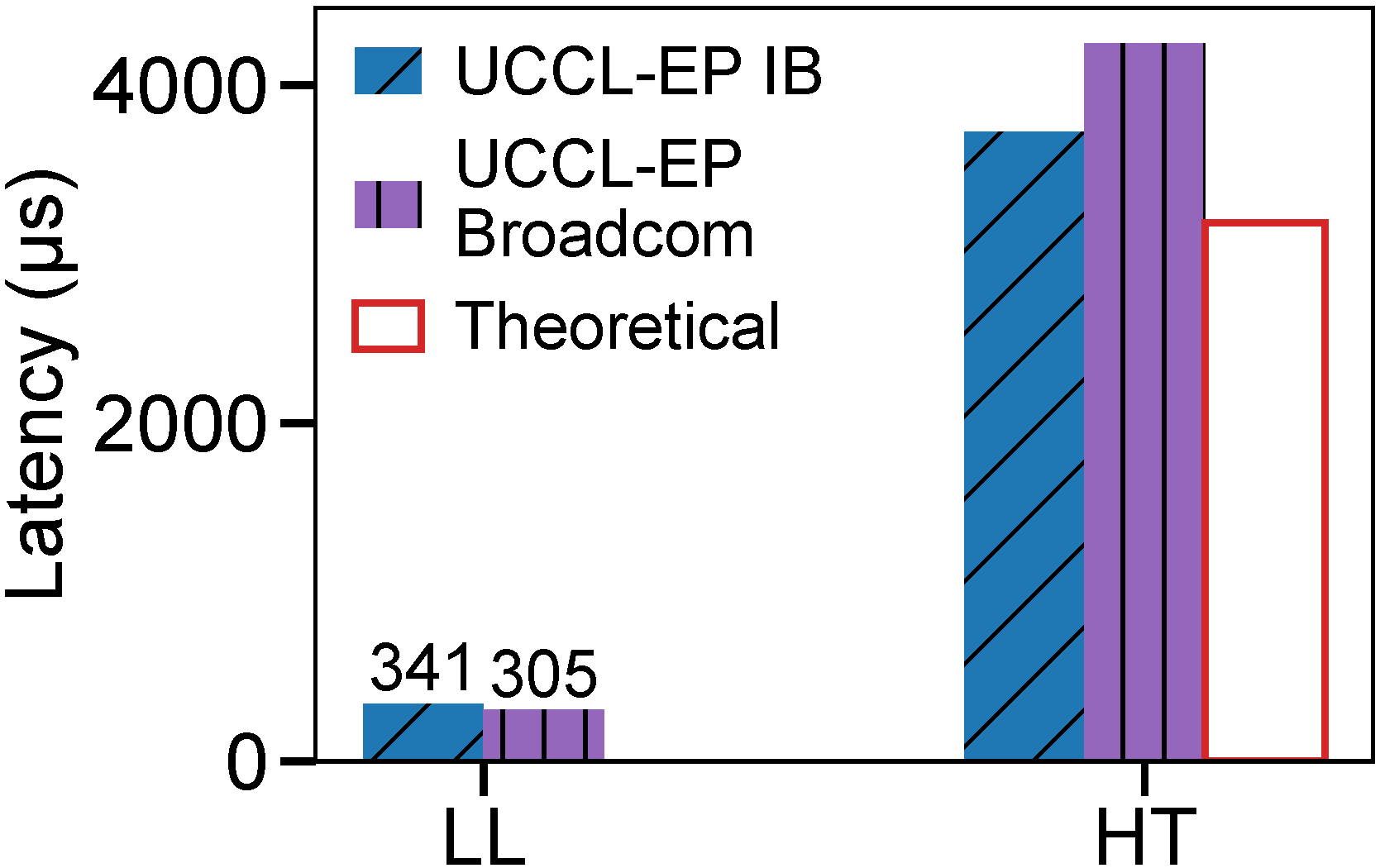
Low-Latency Mode (AMD MI300X + CX7 RoCE)
| #EP | Dispatch Latency | Dispatch BW | Combine Latency | Combine BW |
|---|---|---|---|---|
| 8 | 65 us | 114 GB/s | 92 us | 157 GB/s |
| 16 | 136 us | 55 GB/s | 207 us | 70 GB/s |
| 32 | 224 us | 30 GB/s | 341 us | 42 GB/s |
Porting to AMD GPUs
UCCL-EP’s CPU proxy architecture makes porting to new GPU vendors straightforward — only the GPU kernels need to change, while the CPU-side NIC code remains identical. Porting to AMD GPUs and AWS EFA NICs took only 3 person-months.
The key changes for AMD included:
- Migrating CUDA PTX intrinsics (atomics, memory fences, timers) to ROCm alternatives
- Switching
WARP_SIZEfrom 32 to 64 to match AMD wavefronts - Replacing NVIDIA TMA-based data copy with AMD CU-based (compute unit) copy
- Merging “coordinator” wavefronts into “receiver” wavefronts in the HT kernel, since AMD GPUs support fewer wavefronts but more threads per wavefront
After these GPU-side changes, UCCL-EP immediately ran on AMD platforms with any supported NIC (CX7 RoCE, Broadcom Thor-2, Pollara AI NIC) — no per-NIC work was needed.
Application Results
Megatron-LM Training on AMD (MI300X + Broadcom)
We evaluate end-to-end Megatron-LM training of DeepSeek-V3 (downscaled to 32 layers and 379B parameters) on 16 MI300X nodes using the AMD Primus/Megatron-LM framework.
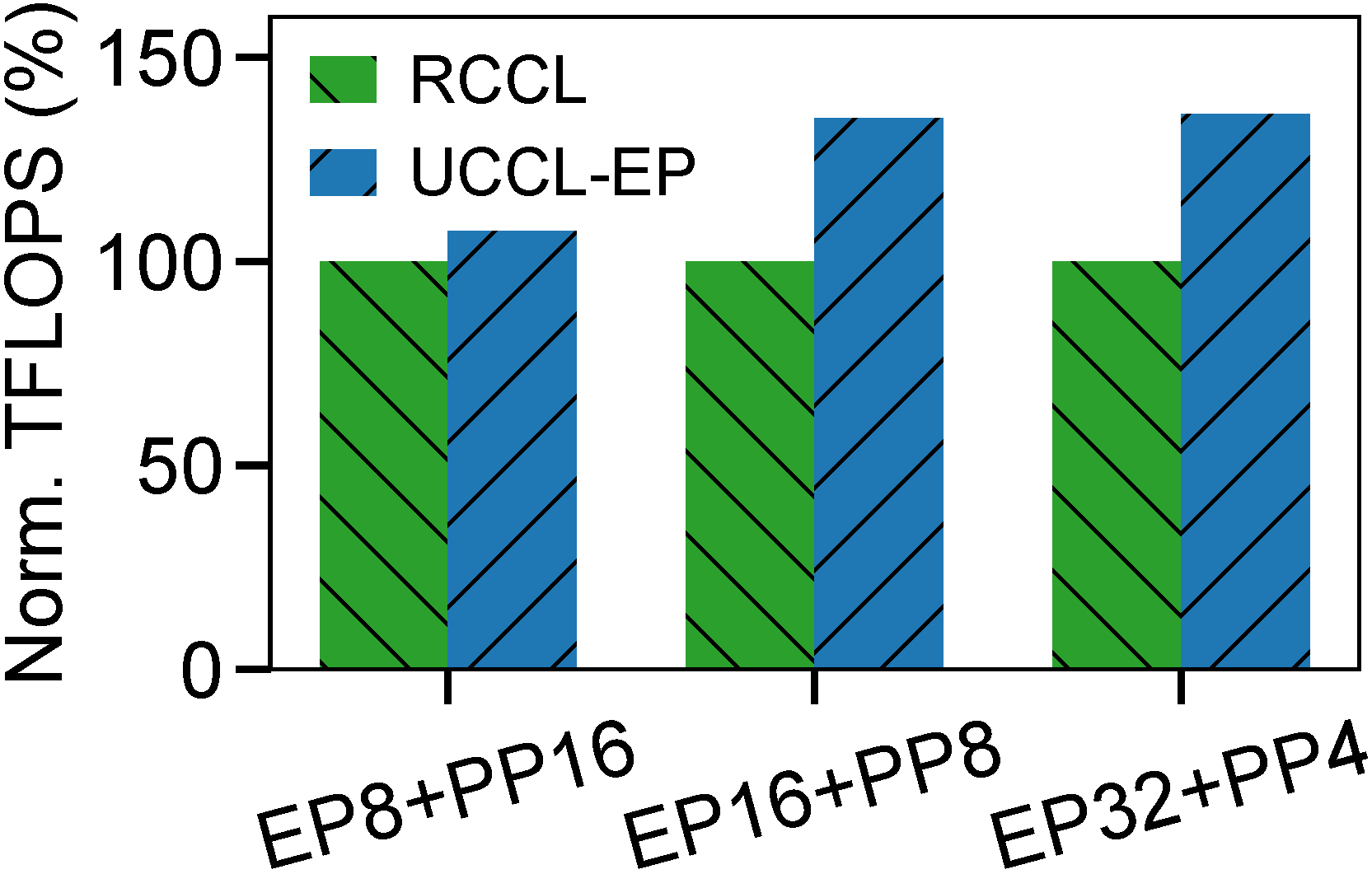
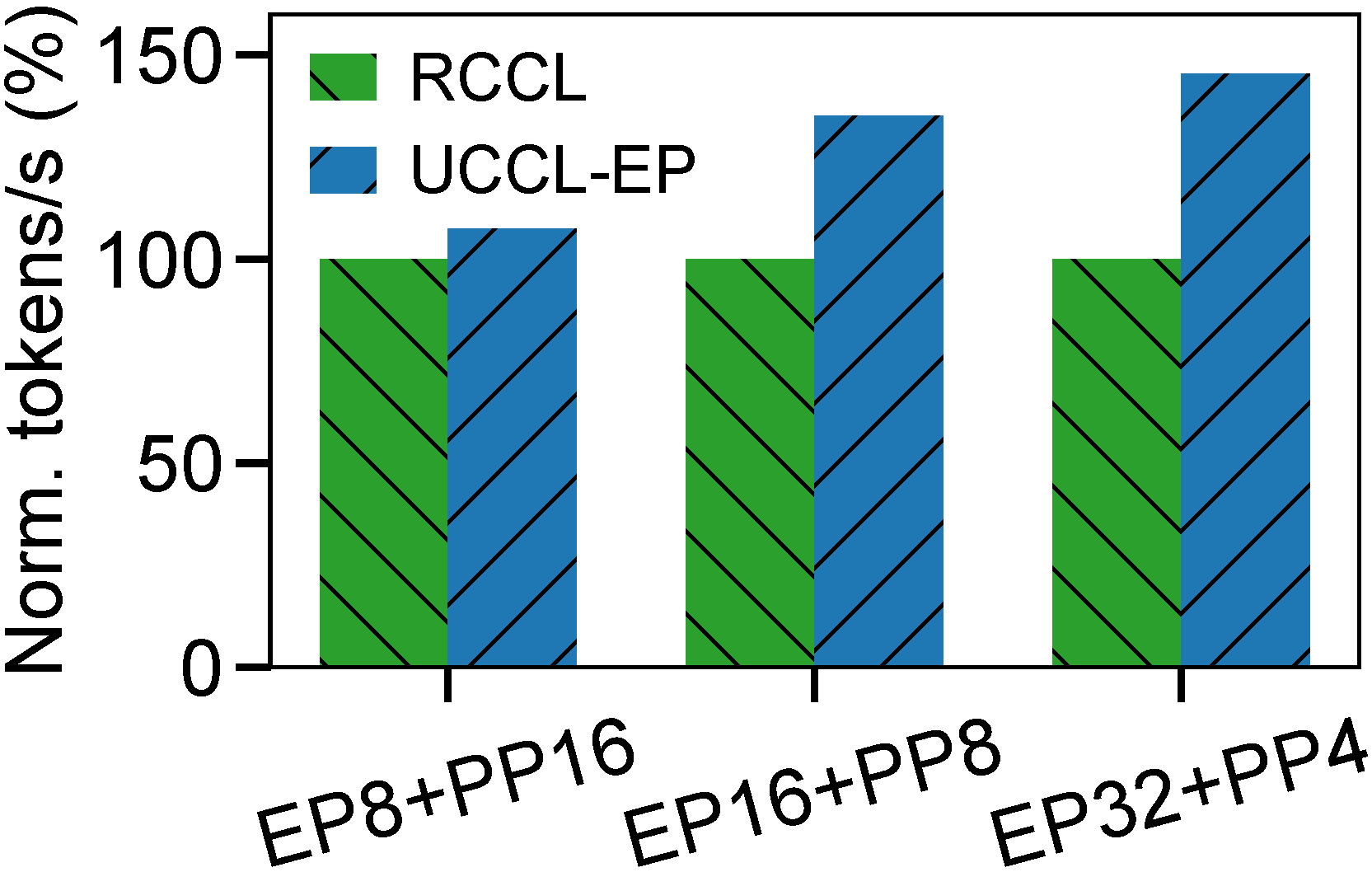
Megatron-LM training throughput (TFLOPS and tokens/s) on 16-node AMD MI300X + Broadcom Thor-2.
Across all configurations, UCCL-EP matches or exceeds the TFLOPS by 7–36% and throughput by 7–45% compared to RCCL. These results show that UCCL-EP provides significant performance benefits for MoE training on AMD hardware.
SGLang Inference on AWS (NVIDIA + EFA)
We evaluate UCCL-EP in SGLang v0.5.3 on a prefill-heavy workload on p5en instances. We compare against NCCL, as DeepEP cannot run on EFA and PPLX had not been integrated into open-source inference engines at the time of evaluation.
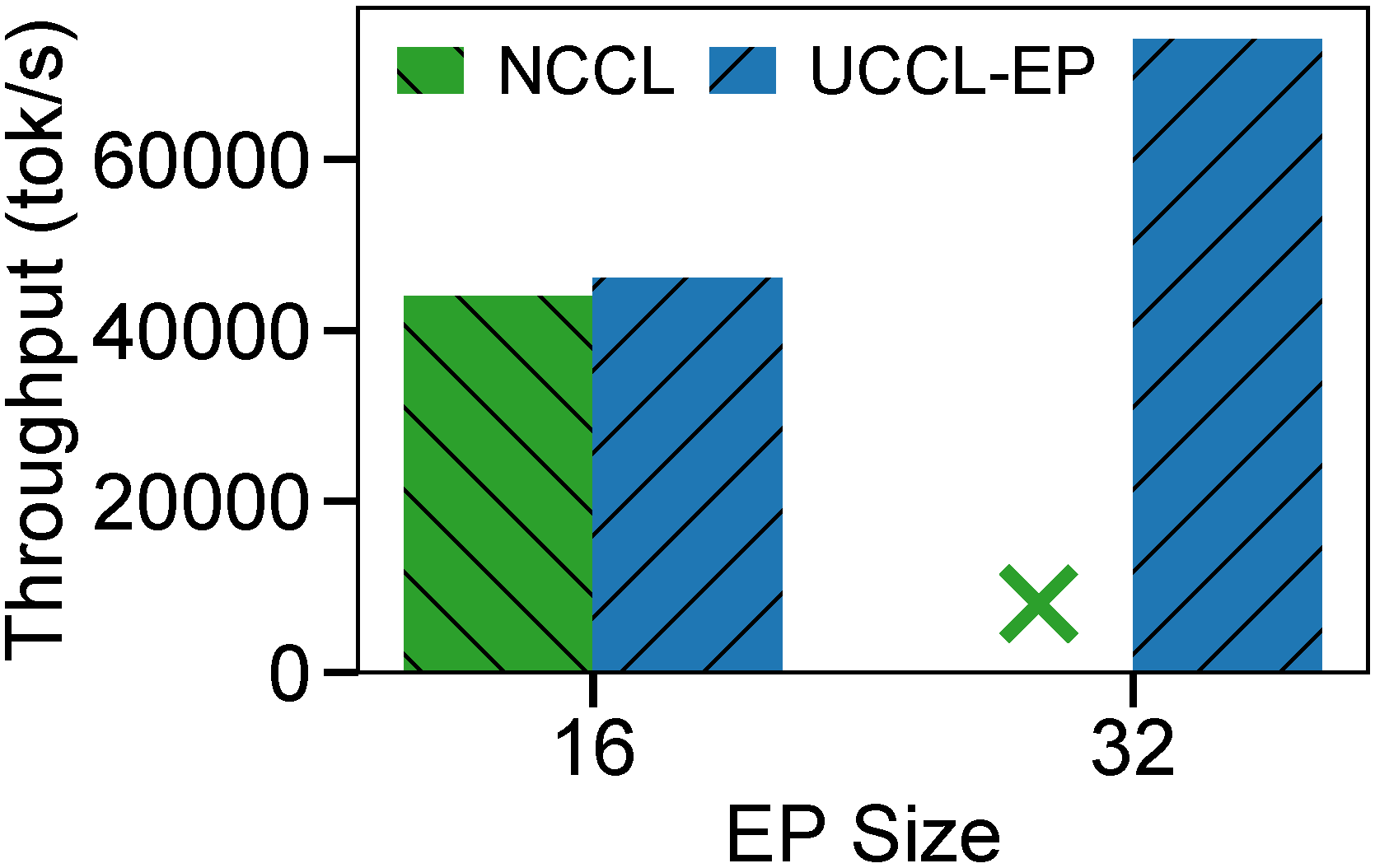
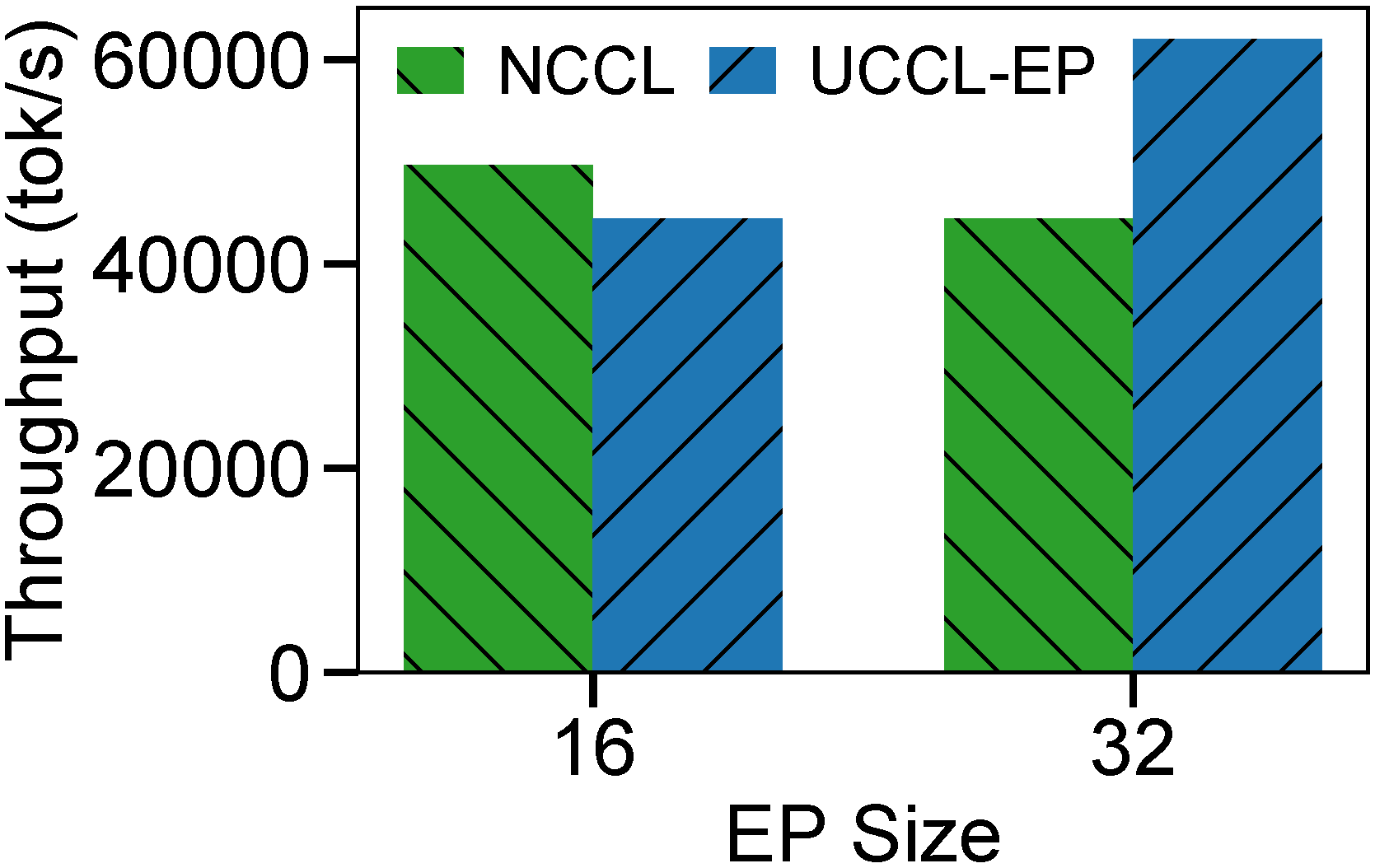
SGLang throughput comparison using UCCL-EP vs. NCCL on p5en. Left: DeepSeek R1 (671B). Right: Qwen3 (235B).
DeepSeek R1 (671B):
- EP=16: UCCL-EP reaches 46K tok/s input throughput, about 5% higher than NCCL.
- EP=32: UCCL-EP improves to 74K tok/s, a 1.6x speedup over its own EP=16 run.
Qwen3 (235B):
- EP=32: UCCL-EP reaches 62K tok/s vs. 44K tok/s for NCCL — about 40% higher throughput.
UCCL-EP enables larger EP configurations (EP=32) where NCCL either significantly underperforms or cannot run. CPU utilization increases modestly from an average 8% to 22%.
Towards More Efficient Low-latency kernels
UCCL-EP’s low-latency (LL) kernel, extending DeepEP, currently issues one 7 KB token per RDMA message. On EFA NICs, this is suboptimal because the current EFA firmware cannot process small tokens at a high enough rate (AWS has confirmed they are working on a firmware fix). PPLX, by contrast, packs tokens into larger messages, giving it an advantage at small batch sizes.
A natural optimization is to pack tokens in a best-effort manner before sending. On the latest UCCL-EP, we have implemented per-expert batching of tokens for low-latency mode. On p5en (EP32, 128 tokens), batching improves BF16 dispatch from 299 us to 268 us (10.4% improvement) and FP8 dispatch from 217 us to 178 us (18.0% improvement). After batching, UCCL-EP outperforms PPLX by 51% on BF16 dispatch and 50% on FP8 dispatch.
We evaluate these LL improvements on p5en while comparing against PPLX on both FP8 and BF16 dispatch paths (see the fair-comparison figure below).
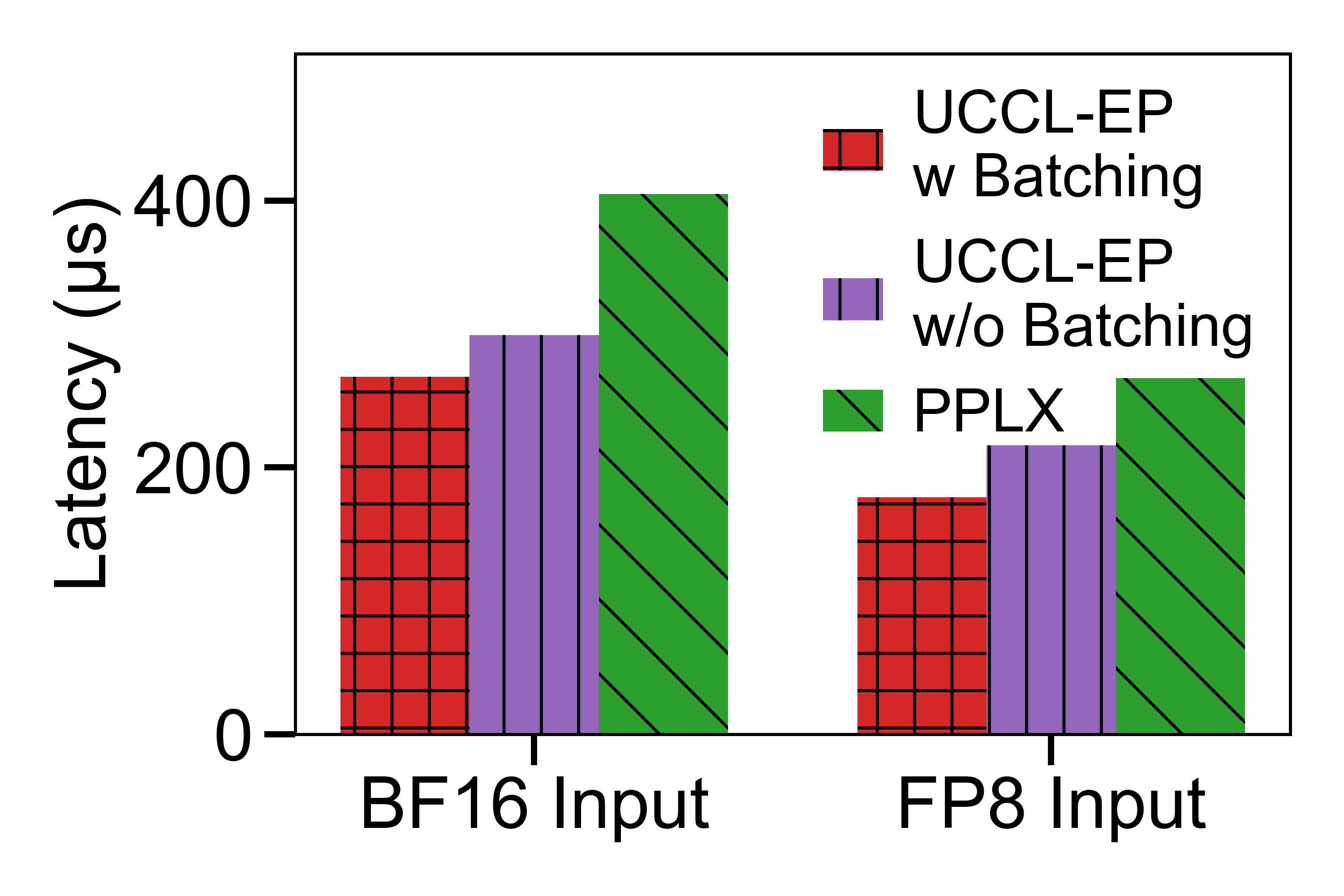 P5en comparison with PPLX for BF16 and FP8 dispatch paths.
P5en comparison with PPLX for BF16 and FP8 dispatch paths.
A Note on Fair Comparison with PPLX Kernels: PPLX uses a different measurement methodology than our original DeepEP-inherited setup. To ensure fairness, we evaluate the results above using a script that aligns with the PPLX measurement methodology. One caveat is that PPLX does not support in-kernel BF16->FP8 conversion. For fairness, the FP8 results we report include BF16->FP8 casting time before entering the PPLX kernel (266.90 us). The PPLX dispatch time excluding external BF16->FP8 pre-cast time is 232.30 us.
Enabling Flow Control
A key advantage of UCCL-EP’s CPU proxy architecture is the ability to implement flow control — which otherwise is difficult with IBGDA, where GPU threads typically blindly issue one-sided RDMA operations without awareness of NIC queue pressure or completion.
We observe that the number of outstanding RDMA requests can have a significant impact on various NICs, particularly affecting tail latency. This becomes increasingly critical as the number of destinations increases, where a single straggler can slow down the entire dispatch or combine operation.
We illustrate this on Broadcom Thor-2 (EP32, normal mode) by sweeping communication configurations, such as various NVLink chunk sizes and RDMA chunk sizes. Without flow control, non-optimal configurations catastrophically degrade — bandwidth can collapse from ~49 GB/s to as low as 4.4 GB/s, and notify latency can explode from hundreds of microseconds to over 70 ms. With flow control (e.g., 1.5 MB inflight limit), performance is stable across all configurations.
UCCL-EP’s CPU proxy supports request tracking and pacing:
- If outstanding requests grow too high, the proxy temporarily buffers messages at the sender to avoid incast at the receiver.
- The proxy can shard outgoing requests across multiple NICs and QPs to avoid congestion and adapt to NIC-specific characteristics.
This is particularly important for Broadcom Thor-2 and AMD Pollara AI NICs. We provide the environment variables UCCL_IB_MAX_INFLIGHT_BYTES and UCCL_IB_MAX_INFLIGHT_NORMAL to configure flow control. Without it, these NICs can encounter CQE error 12 (Transport Retry Counter Exceeded) under high load.
Acknowledgements
This research is supported by gifts from Accenture, AMD, Anyscale, AWS, Broadcom, Cisco, Google, IBM, Intel, Intesa Sanpaolo, Lambda, Lightspeed, Mibura, Microsoft, NVIDIA, Samsung SDS, and SAP.