CommBench: Can LLMs Write Correct and Efficient GPU Communication Code?
By: Shuang Ma, Yuyi Li, Yihan Zhang, Danyang Chen, Shuyang Ji, Ziming Mao, Cheng Ji, Ansha Prashanth, Wenting Yang, Yiran Wang, Chihan Cui, Peiyu Lin, Amanda Raybuck, Ion Stoica, Yang Zhou.
Date: June 9, 2026
GPU communication is a critical component of large-scale LLM training and inference, yet its complexity makes it challenging for code-generation models. We present CommBench, a benchmark with 100+ GPU communication problems + reference solutions (collectively called examples) that cover industry-level multi-device communication use cases based on UCCL's development experience. CommBench spans point-to-point, collective, expert-parallel, compute and communication fusion, and utility functions. These examples are either hand-written by GPU communication experts or distilled from production codebases such as Mscclpp, NCCL, NVSHMEM, DeepEP, ThunderKittens, vLLM, and SGLang. We then evaluate leading closed and open models under a cheat-resistant harness on real hardware spanning intra-node NVLink and inter-node RDMA, and present case studies of where and why they succeed or break down. As future work, we plan to post-train LLMs on these datasets to close this gap.
CommBench open-source: uccl-project/CommBench (MIT license).
Why Writing GPU Communication Code Matters—and Why It Remains Challenging for LLMs?
Communication and compute-communication fusion are essential for scaling modern LLM training and inference. In production training, communication can consume 43.6% of the forward pass 1; in MoE inference with wide expert parallelism, inter-device communication accounts for up to 47% of total execution time 2. Getting this code right and fast is not a nice-to-have.
The demand for customized GPU communication and compute-communication fusion is rapidly growing. Established libraries like NCCL offer comprehensive interfaces, but optimize for generality over frontier performance. As a result, companies often maintain in-house GPU communication and computation stacks for tighter control and optimization. GPU communication also remains a rapidly evolving area: new hardware and new LLM architectures continuously introduce new requirements for higher performance and specialized workloads, while communication abstractions are still evolving:
- Modern GPUs are extremely powerful and expensive, motivating highly customized kernels and tighter compute–communication fusion to maximize hardware utilization across architectures such as Hopper, Blackwell, and AMD GPUs. As GPUs become faster, communication increasingly needs to be initiated directly from GPUs instead of relying on CPU-mediated execution paths used in traditional libraries such as NCCL.
- New LLM architectures, such as MoE expert parallelism, introduce increasingly irregular and fine-grained communication patterns that are not well supported by existing collective libraries.
Multi-device GPU programming is inherently harder than single-device coding, for three reasons:
- It demands niche expertise, requiring deep knowledge of both GPU kernels and networking.
- It requires coordinating many devices over fail-prone interconnects, which is intrinsically difficult.
- It lacks data, as practical, faithful datasets for GPU communication are largely missing.
Despite all this, multi-device GPU programming has been largely overlooked in LLM coding benchmarks. HumanEval, MBPP, LiveCodeBench — these measure single-device reasoning. No existing benchmark evaluates whether a model can generate correct GPU communication code, including communication primitives (e.g., Mscclpp channels and collective interfaces) and compute–communication fusion kernels (e.g., fused AllGather+GEMM across NVLink and InfiniBand).
Benchmark and Framework Structure
Benchmark Structure
The dataset is organized as a list of independently runnable examples, currently with 100+ such examples. Some implement complete, ready-to-use functionality (e.g., P2P/collective interfaces, or MoE expert-parallel dispatch and combine); others are reusable communication building blocks (e.g., Mscclpp channels). Drawing on our hands-on experience from the UCCL project, we manually assign each example one of three difficulty levels: Easy / Medium / Hard.
Some examples we hand-wrote on top of base libraries; others are extracted from production-grade communication and LLM-serving frameworks. By function, they fall into:
- P2P — point-to-point transfer between a pair of devices.
- Collective — group operations across all ranks (AllReduce, AllGather, All-to-All, …).
- EP — dynamic, non-uniform dispatch/combine traffic for MoE models.
- Fusion — kernels that interleave communication with compute (e.g., AllGather+GEMM).
- Utilities — supporting components such as connection setup, buffer registration, and topology queries.
By source, they span cuda-runtime, libibverbs, Mscclpp, nccl, nvshmem, deepep, nccl-device-api, thunderkittens, vllm, and sglang.
Framework Structure
We built a framework that automatically evaluates different models on the dataset and supports multi-round refinement of generated code. Careful design of each example and its execution environment enforces strict checking and prevents the model from cheating.
Example structure. Each example has three parts:
- Reference solution (excluded from the repo) — high-quality, hand-written code organized in an object-oriented style (Python / CUDA / HIP / C++). It ships with a test harness that uses randomized inputs, so a model cannot hard-code expected outputs. We keep the reference solutions secret to prevent them from leaking into model training data and contaminating future evaluations.
- Problem statement + empty solution — the reference with its core implementation stripped out and marked
// TODO, but with the functional interface preserved. This file becomes part of the prompt: the model must honor the interface semantics, which also keeps its output directly testable. We verify that only the regions meant to be edited were changed, guarding against cheating. - Build-and-run script — independently compiles and runs an example (reference or generated) and is hidden from the model. By controlling the compile command, we strictly ensure the generated code uses only the intended libraries.
Multi-round refinement. When max-round > 1, if the generated code fails to run or underperforms the reference, we feed the compile/run output back into the prompt and ask the model to iterate — repeating until performance improves or the round limit is reached.
Testbed. We evaluate on three clusters that together span NVLink, InfiniBand, and RoCE on both NVIDIA and AMD GPUs: (1) a single node of 8× NVIDIA B300 over NVLink; (2) NVIDIA GH200 nodes linked by 400 Gb/s InfiniBand (ConnectX-7 / BlueField-3) for inter-node RDMA; and (3) 8× AMD Instinct MI325X nodes with intra-node Infinity Fabric (XGMI) and 400 Gb/s RoCE inter-node RDMA. This lets CommBench exercise real inter-node RDMA paths, not only intra-node NVLink, across both vendors’ stacks (CUDA and ROCm/HIP).
Leaderboard
Sorted by Pass×GM ⭐ — pass rate scaled by geometric-mean code quality on passing examples. Bars
▓░show each value on an absolute 0–100% scale (Pass×GM and GM‑Speedup as a fraction of 1.0).
| Rank | Model | Pass×GM | Pass Rate | PASS+Good | GM‑Speedup | Open Source | Price |
|---|---|---|---|---|---|---|---|
| 🥇 | gpt-5.5 | 🟢 0.467 ▓▓▓▓░░░░ | 🟢 57.4% ▓▓▓▓▓░░░ | 🟢 30.7% ▓▓░░░░░░ | 🔴 0.813 ▓▓▓▓▓▓▓░ | ❌ | $1.91 |
| 🥈 | gemini-3.1-pro-preview | 🟡 0.305 ▓▓░░░░░░ | 🟡 36.6% ▓▓▓░░░░░ | 🟢 25.7% ▓▓░░░░░░ | 🔴 0.832 ▓▓▓▓▓▓▓░ | ❌ | $0.26 |
| 🥉 | claude-opus-4-7 | 🟡 0.282 ▓▓░░░░░░ | 🟡 33.7% ▓▓▓░░░░░ | 🟡 20.8% ▓▓░░░░░░ | 🔴 0.836 ▓▓▓▓▓▓▓░ | ❌ | $0.21 |
| 4️⃣ | glm-5.1 | 🟡 0.281 ▓▓░░░░░░ | 🟡 29.7% ▓▓░░░░░░ | 🟡 17.8% ▓░░░░░░░ | 🟢 0.947 ▓▓▓▓▓▓▓▓ | ✅ | $0.63 |
| 5️⃣ | kimi-k2.6 | 🟡 0.275 ▓▓░░░░░░ | 🟡 30.7% ▓▓░░░░░░ | 🟡 18.8% ▓▓░░░░░░ | 🟡 0.895 ▓▓▓▓▓▓▓░ | ✅ | $0.10 |
| 6️⃣ | qwen3.7-max | 🟡 0.269 ▓▓░░░░░░ | 🟡 26.7% ▓▓░░░░░░ | 🟡 15.8% ▓░░░░░░░ | 🟢 1.008 ▓▓▓▓▓▓▓▓ | ❌ | $0.03 |
| 7️⃣ | deepseek-v4-pro | 🔴 0.197 ▓▓░░░░░░ | 🔴 19.8% ▓▓░░░░░░ | 🔴 12.9% ▓░░░░░░░ | 🟢 0.995 ▓▓▓▓▓▓▓▓ | ✅ | $0.02 |
Color: 🟢 top tier · 🟡 mid tier · 🔴 bottom tier.
Metric Definitions
| Metric | Formula | What it measures |
|---|---|---|
| Pass×GM ⭐ | Pass Rate × GM‑Speedup | Pass rate scaled by geometric-mean code quality on passing examples. Combines coverage and quality: a model that rarely passes but generates very fast code scores the same as one that always passes at reference speed. Primary ranking metric. |
| Pass Rate | PASS / Total | Fraction of examples where code compiled, ran, and produced correct results. |
| PASS+Good | (on_compare + better) / Total | Fraction of all examples with correct and performant code (within −5% of reference). |
| GM‑Speedup | GM over scored PASS of scoreᵢ | Geometric mean of per-example speedup scores over passing examples. The per-example score is scoreᵢ = GMₛ( gen(i,s) / ref(i,s) ), where s iterates over measured data sizes and gen(i,s), ref(i,s) are the performance metrics of the generated and reference code on example i at data size s, expressed so that higher is better (lower-is-better metrics such as latency are inverted to 1/latency first). The choice of primary metric per example is determined by human review. Taking the GM across sizes (rather than averaging absolute throughput first) ensures each data point contributes equally regardless of absolute throughput magnitude; without it, large sizes (e.g. 128 MB at ~100 GB/s) would dominate small ones (e.g. 256 KB at ~5 GB/s). Caveat: computed only over passing examples. A model that passes more (often harder) examples with mediocre performance can show a worse GM‑Speedup, hence we rank by Pass×GM. |
| Price | — | Average cost per example (USD). |
Performance verdict thresholds (4-tier):
better ≥ +20% · on_compare −5% to +20% · degraded −40% to −5% · severely_degraded < −40%
Reasoning effort and model parameters. We run every model at its default reasoning effort and default sampling parameters (temperature, top-p, etc.); we do not tune them. The per-model defaults are: gpt-5.5 = medium, gemini-3.1-pro-preview = high, claude-opus-4-7 = adaptive thinking, glm-5.1 = thinking enabled (the model decides when to think), kimi-k2.6 = thinking enabled (temperature fixed at 1.0), deepseek-v4-pro = medium. The only exception is qwen3.7-max, where thinking is disabled to avoid timeouts.
Analysis: Top vs. Bottom Model
We select the highest- and lowest-scoring models on CommBench, gpt-5.5 (Pass×GM = 0.467) and deepseek-v4-pro (Pass×GM = 0.197), for a detailed breakdown across difficulty levels, task types, library coverage, and code performance.
Difficulty Breakdown
| GPT-5.5 | DeepSeek-V4-Pro |
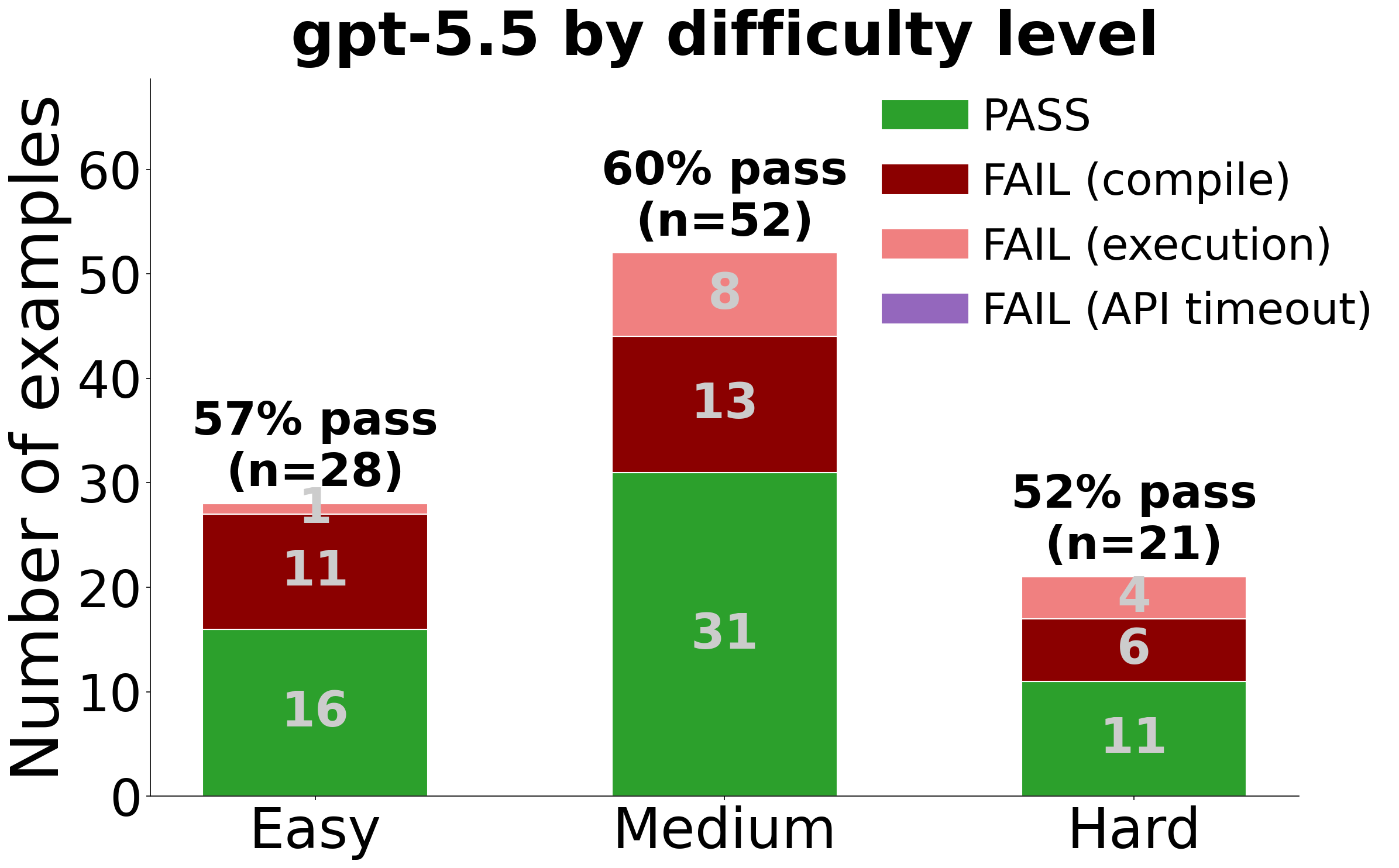 |
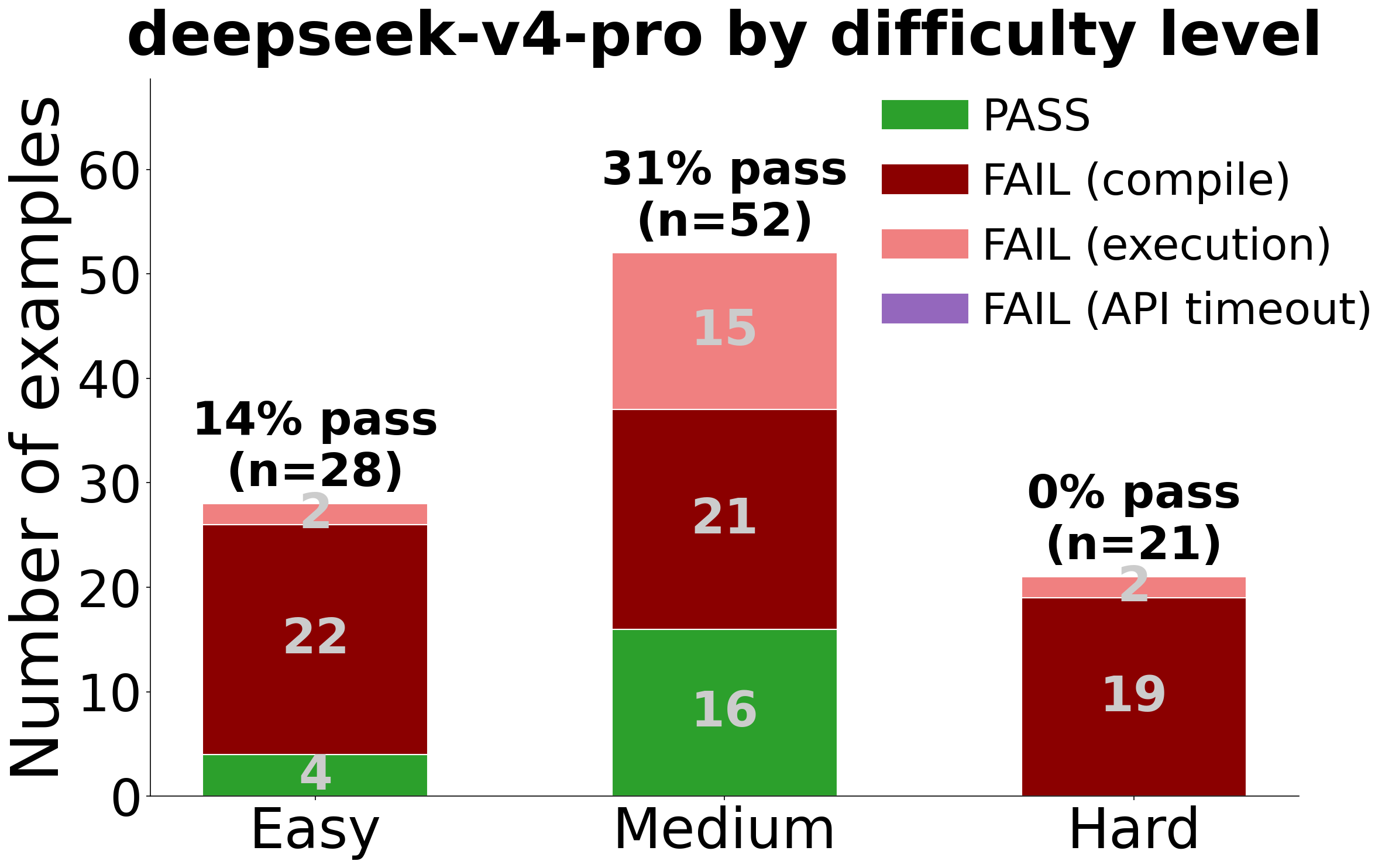 |
Human-defined difficulty does not always align with model difficulty. deepseek’s weak Easy performance (14%) is largely attributable to gaps in library-specific API knowledge — for libraries such as mscclpp and ThunderKittens, it lacks the interface semantics needed to call APIs correctly, causing failures on examples that only require invoking a small number of functions to implement straightforward functionality. On the Hard end, many examples ask the model to implement communication primitives from near-scratch (e.g. AllReduce over NVLink or RDMA) which exposes deepseek’s limited capability on complex GPU communication-compute tasks.
Performance Quality Among PASS Examples
| GPT-5.5 | DeepSeek-V4-Pro |
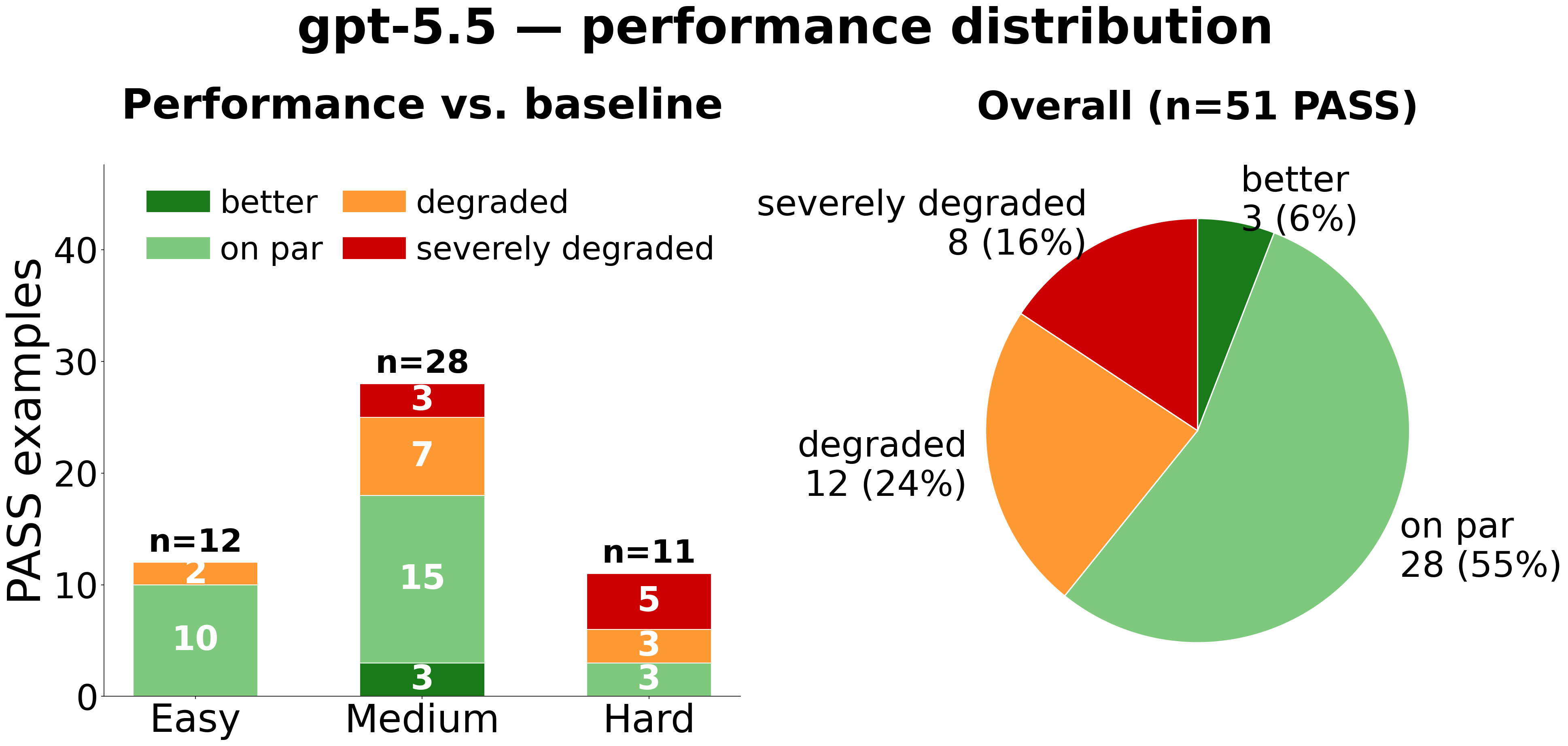 |
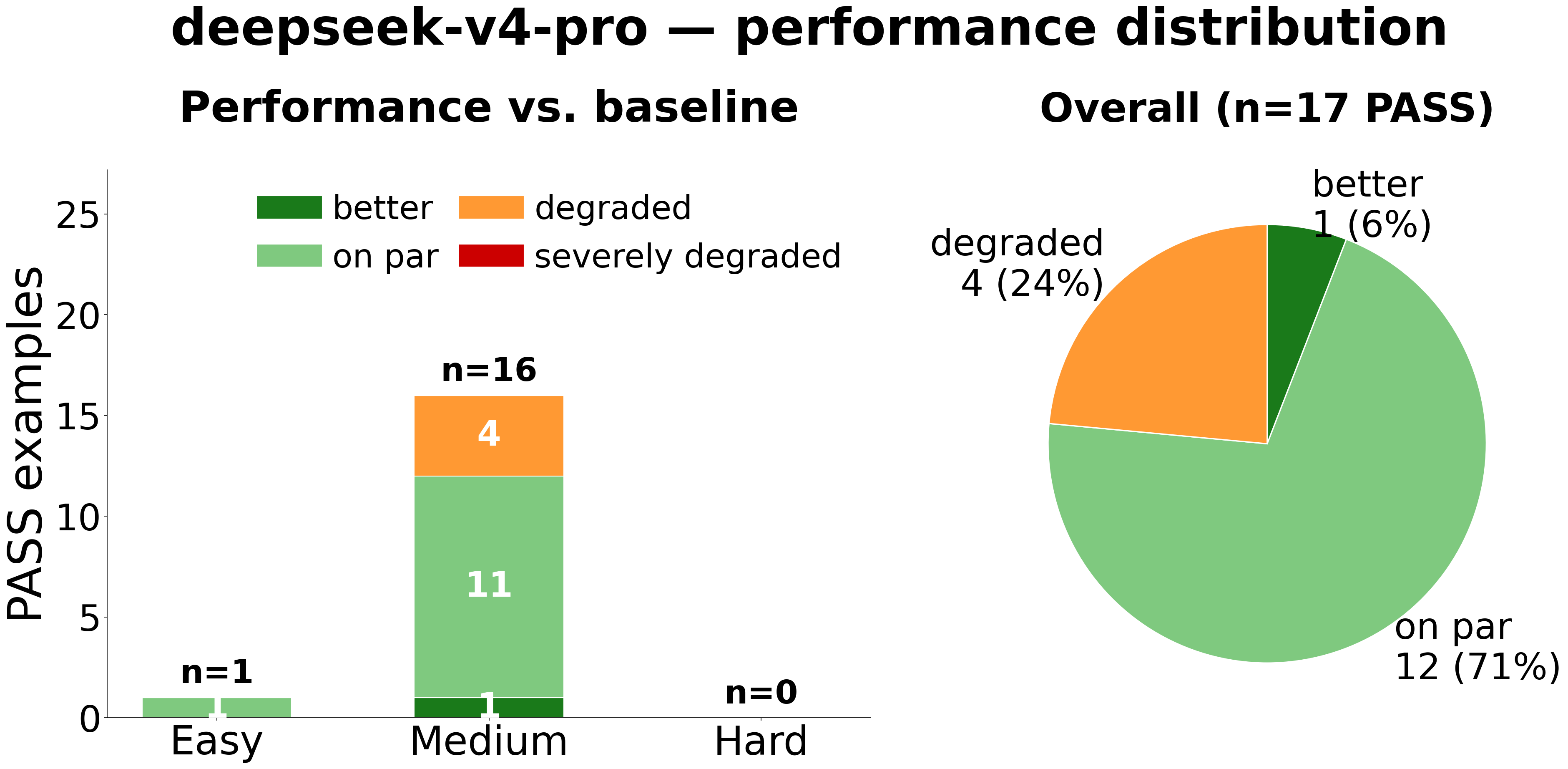 |
gpt-5.5 has the widest quality spread: 8 severely degraded cases (14% of PASS), all concentrated in Hard examples. This is partly because examples that gpt-5.5 manages to compile and run (but with degraded performance) would simply fail to compile or execute under deepseek, and therefore never appear in deepseek’s performance distribution at all.
Tag and Library Coverage
| GPT-5.5 | DeepSeek-V4-Pro |
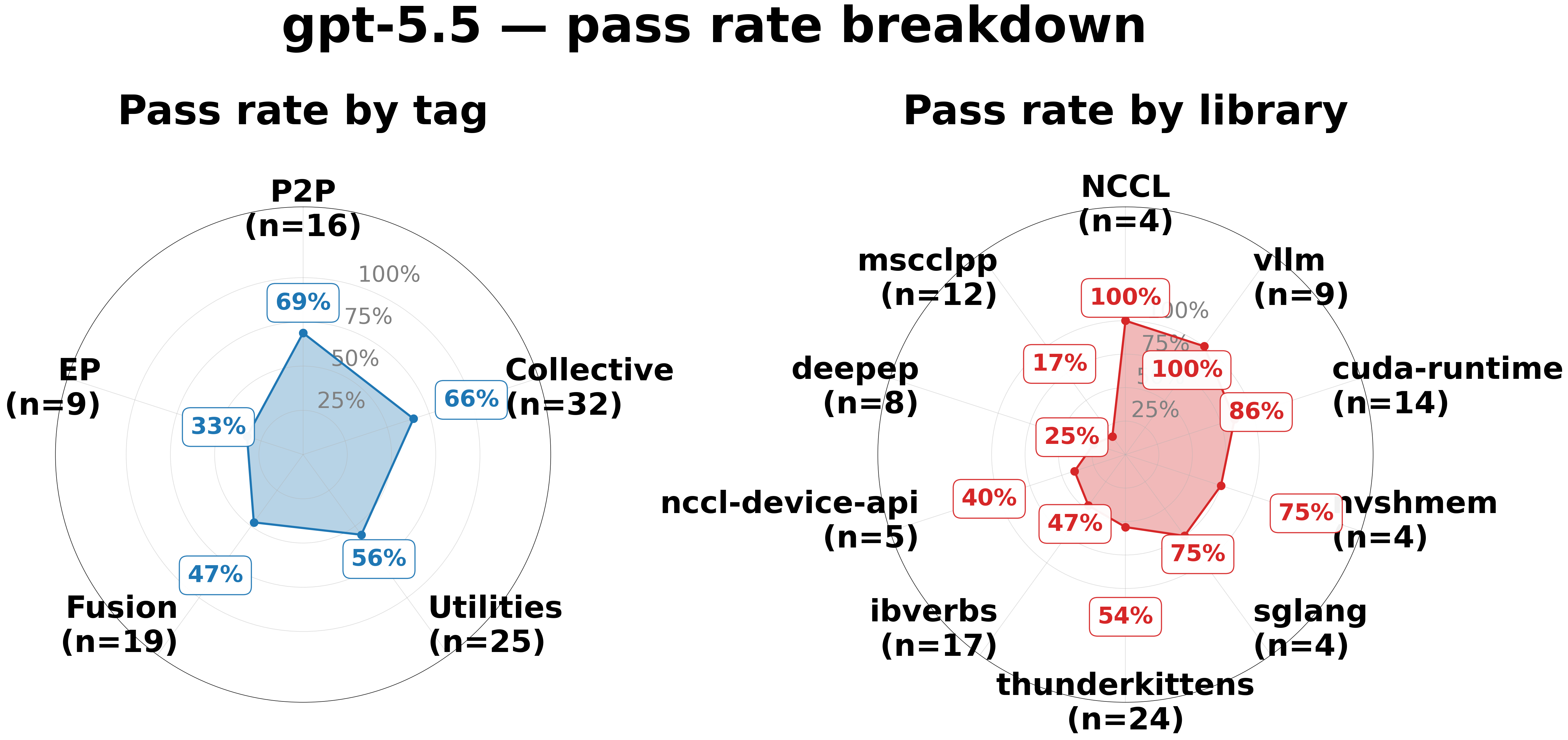 |
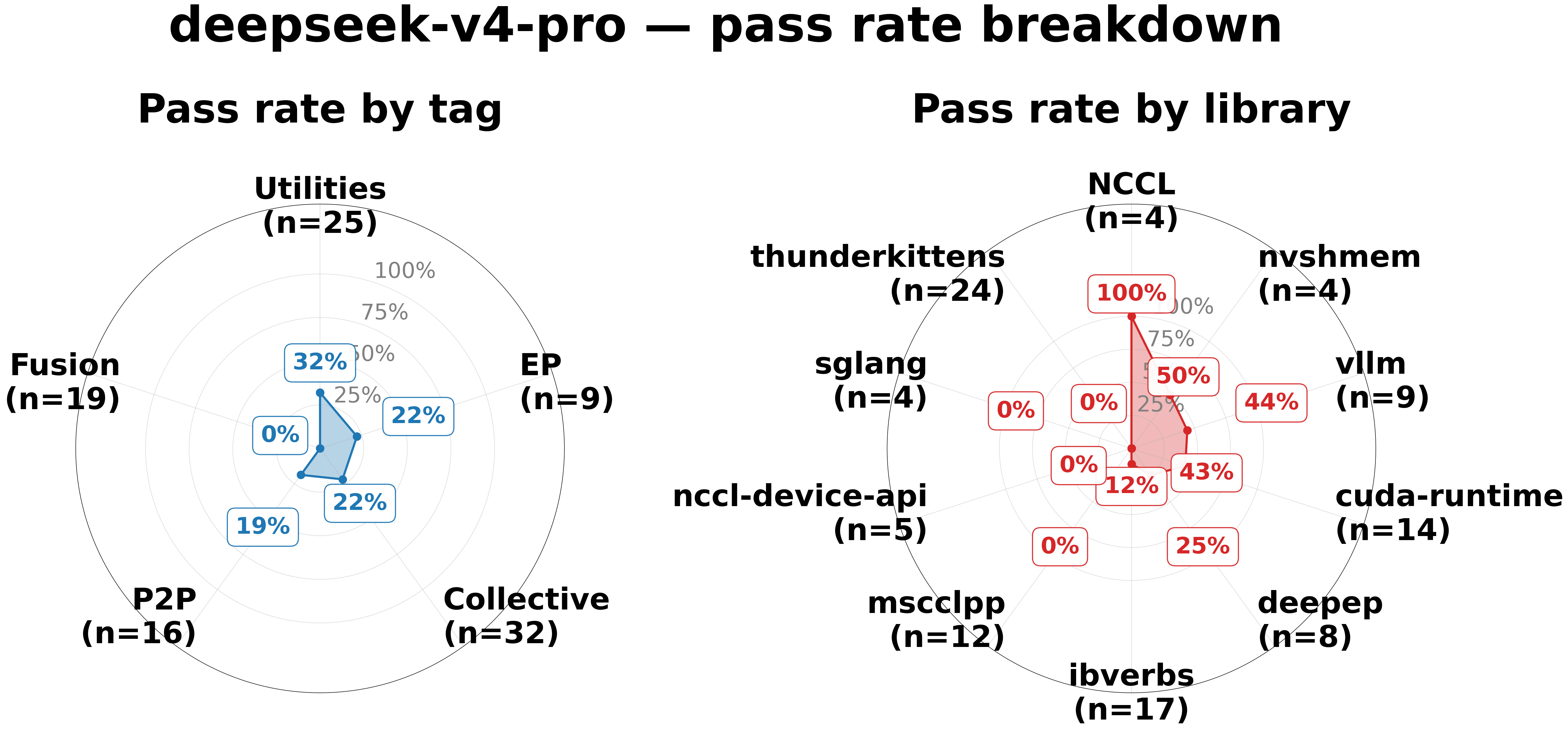 |
gpt-5.5 dominates on Collective (66% vs 22%) and is the only model with meaningful coverage of specialized libraries — mscclpp (17%), nccl-device-api (40%), and thunderkittens (54%). deepseek is competitive on NCCL (100%) and P2P tags, but scores 0% across all three specialized libraries. For widely adopted libraries such as vllm, NCCL, and nvshmem, both models perform well.
DeepSeek with max_rounds = 5
Due to budget constraints, gpt-5.5 was evaluated with a single generation round. Despite deepseek’s weaker first-round performance, its API cost is only ~1% of gpt-5.5’s ($0.02 vs $1.91 per example), which makes multi-round self-correction economically viable. Allowing deepseek up to 5 self-correction rounds substantially changes its profile.
Cumulative PASS by Round
| Round | Cumulative PASS | Pass Rate | New this round |
|---|---|---|---|
| 1 | 16 | 15.8% | |
| 2 | 28 | 27.7% | +12 (largest gain) |
| 3 | 32 | 31.7% | +4 |
| 4 | 34 | 33.7% | +2 |
| 5 | 42 | 41.6% | +8 |
Difficulty Breakdown: max=1 vs max=5
| DeepSeek max=1 | DeepSeek max=5 |
|
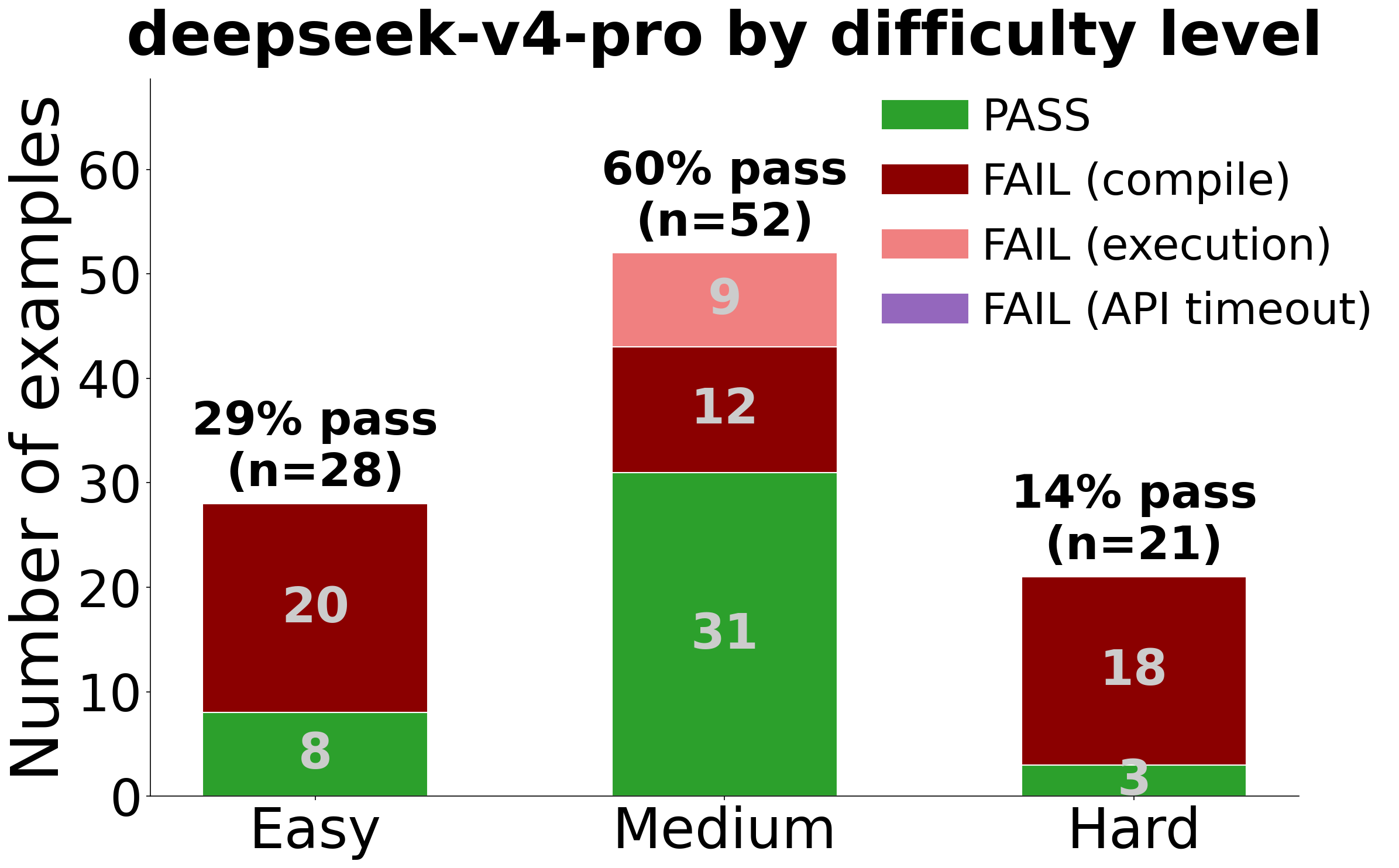 |
Performance Quality and Library Coverage (max=5)
| Performance distribution among PASS examples | Tag & library coverage |
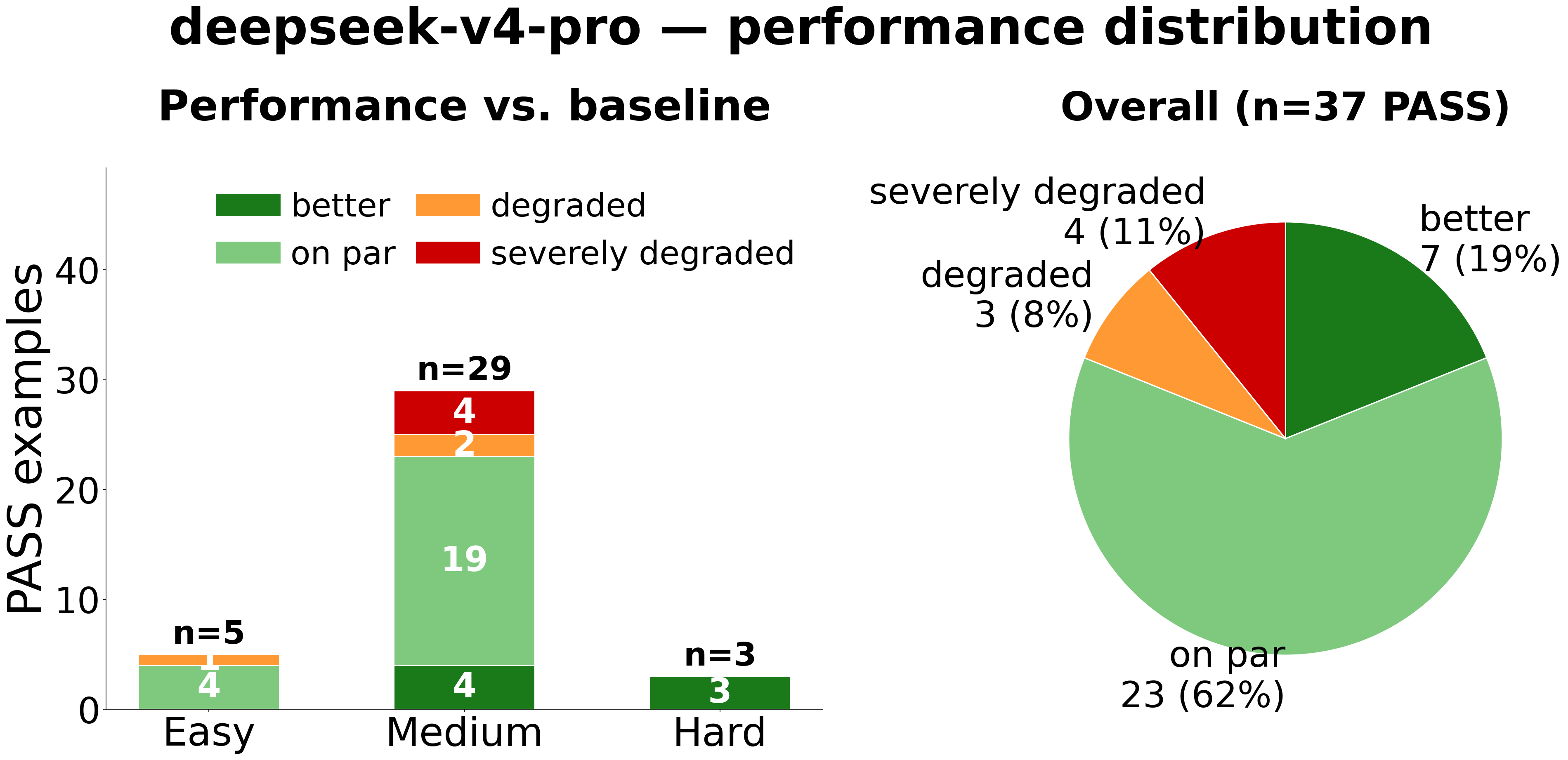 |
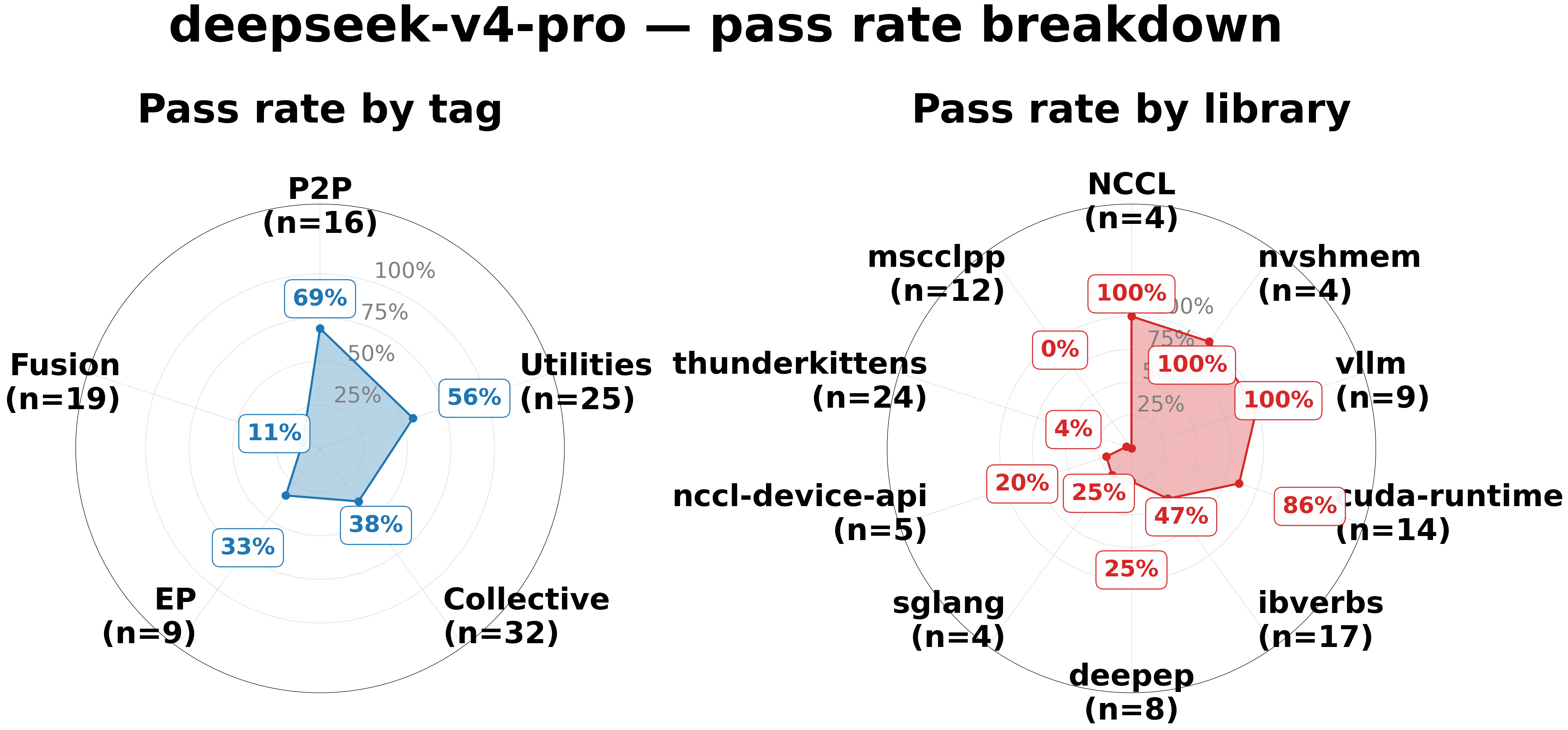 |
Multi-round self-correction more than doubles deepseek’s overall pass rate (16→42, 15.8%→41.6%) and substantially unlocks Medium-difficulty commodity-library tasks (31% → 60%). It does not unlock Hard examples or specialized libraries (mscclpp: 0%, thunderkittens: 4%) — those require domain knowledge the model does not have. The practical implication: deepseek with retries is a reasonable choice when tasks are restricted to commodity libraries (NCCL, vllm, cuda-runtime, nvshmem) and a retry budget is acceptable.
Case Studies
Case 1: Partial Pass — ThunderKittens AllToAll
Example 049 — ThunderKittens AllToAll ↗
Level 🟢 Easy · Tag Collective · Library thunderkittens
Task: Implement a BF16 multi-GPU AllToAll kernel using the ThunderKittens library, using TMA (Tensor Memory Accelerator) for tile-level data movement between GPU shards over NVLink.
What to implement: Two small device-side kernels: all_to_all::kernel (TMA-load one tile from local input, TMA-store to destination device’s output shard) and all_to_all_barrier::kernel (one-line barrier_all synchronization). All host scaffolding is provided.
Why most models failed: Both kernels are under 10 lines and only require calling existing ThunderKittens interfaces, with no custom algorithm needed. The failure root is ThunderKittens-specific API knowledge: type scoping (all_to_all::globals::shared_tile vs bare shared_tile), the correct tma::load_async argument signature, and the shared_allocator::allocate template usage. ThunderKittens is a niche research library with minimal training-data coverage, causing models to mis-scope types, hallucinate non-existent APIs, or use wrong argument forms.
Per-Model Summary
| Model | Rounds | Outcome | Perf vs Ref | Failure Pattern |
|---|---|---|---|---|
| gpt-5.5 | 1 | PASS | on_par (−0.23%) | — |
| claude-opus-4-7 | 1 | PASS | on_par (+0.17%) | — |
| deepseek-v4-pro | 5 | Compile error (r1–r2, r4–r5) / Link error (r3) | — | r1: hallucinated ThunderKittens API (tma::semaphore, tma::init_semaphore, tma::wait, wrong barrier_all form — none exist); r2: structural C++ errors (__global__ written as member function, duplicate class definition, wrong CUDA driver API types); r3: compiled but no main() → linker undefined reference to 'main'; r4: used CUDA_CHECK macro without defining it; r5: early type/template error triggered 43 cascading STL errors |
| gemini-3.1-pro-preview | 1 | Compile error | — | shared_tile used without all_to_all::globals:: namespace qualifier |
| kimi-k2.6 | 1 | Compile error | — | Same unqualified shared_tile reference |
| glm-5.1 | 1 | Compile error | — | Wrong type passed to shared_allocator::allocate |
| qwen3.7-max | 1 | Compile error | — | Wrong argument types for tma::load_async |
Case 2: A Case All LLMs Failed
Example 072 — GPU Barrier Within CTA ↗
Level 🟡 Medium · Tag Utilities · Library cuda-runtime
Task: Implement intra-CTA producer/consumer synchronization using a Hopper/Blackwell shared-memory mbarrier with a non-blocking try_wait probe, a pattern used in persistent-kernel tile pipelines (e.g., CUTLASS, Mirage) to overlap data arrival with computation without stalling the warp scheduler.
What to implement: Three inline-PTX device helpers (initialize_barrier, arrive, try_wait_barrier) and a benchmark kernel body, lifted from Mirage.
Why all models failed: This task only requires using a small set of well-defined mbarrier interfaces, which is the kind of API memorization LLMs are expected to excel at. However, mbarrier is Hopper-specific PTX introduced in sm_90, and models may lack sufficient training data for these instructions, making them prone to mis-remembering argument counts, ordering, or address-space requirements.
Per-Model Failure Summary
| Model | Rounds | Outcome | Failure Pattern |
|---|---|---|---|
| deepseek-v4-pro | 5 | Compile error | Wrong PTX register constraint (r1); missing mbarrier.arrive destination operand (r2–r5) |
| gpt-5.5 | 1 | Deadlock | Deadlock: consumer runs before producers due to warp branch ordering; no kProbeBound guard so kernel hangs forever |
| gemini-3.1-pro-preview | 1 | Correctness FAIL | Deadlock: consumer runs before producers; exits via kProbeBound and reads uninitialized tile |
| claude-opus-4-7 | 1 | Correctness FAIL | Deadlock: consumer runs before producers; also incorrect phase ^= 1 since mbarrier.init resets parity to 0 each iteration |
| glm-5.1 | 1 | Runtime error | Inline-asm operand index confusion |
| kimi-k2.6 | 1 | Compile error | Hallucinated CUDA intrinsic name |
| qwen3.7-max | 1 | Correctness FAIL | Wrong PTX register constraint ("l" instead of "r") |
Case 3: All LLMs Failed — Niche Library API with No Algorithmic Hints
Example 086 — mscclpp AllToAll (Hard) ↗
Level 🔴 Hard · Tag Collective · Library mscclpp
Task: Implement the fastest intra-node AllToAll kernel using MSCCL++ 3 MemoryChannel primitives. The template provides no algorithmic description — only a minimal comment “implement the fastest All to All CUDA kernel” and a set of empty // TODO stubs.
What to implement: One GPU kernel (alltoall2) using MemoryChannel for direct peer writes, and the full host-side All2All class (constructor, buffer allocation, channel setup, launch, correctness verification, barrier).
Why all models failed: The task requires models to implement a functionally complete, semantically correct intra-node AllToAll from scratch (device kernel, host class, channel setup, buffer management, and correctness verification), all consistent with MSCCL++‘s MemoryChannel interface contract, with no algorithmic hints provided. This is hard even for an expert programmer unfamiliar with mscclpp. Every model failed at compile time: mscclpp headers and class interfaces are largely absent from training data, causing models to hallucinate non-existent header paths and method signatures before reaching any algorithmic logic.
Per-Model Failure Summary
| Model | Rounds | Outcome | Failure Pattern |
|---|---|---|---|
| deepseek-v4-pro | 5 | Compile error | r1: used mscclpp types with no includes (namespace undefined); r2–r5: each round invented a different non-existent mscclpp header |
| gpt-5.5 | 1 | Compile error | Included some mscclpp headers but missed the one for MemoryChannel; also hallucinated a wrong class name |
| gemini-3.1-pro-preview | 1 | Compile error | Hallucinated mscclpp API |
| claude-opus-4-7 | 1 | Compile error | Hallucinated mscclpp API |
| glm-5.1 | 1 | Compile error | Hallucinated mscclpp API |
| kimi-k2.6 | 1 | Compile error | Hallucinated mscclpp API |
| qwen3.7-max | 1 | Compile error | Hallucinated mscclpp API |
Conclusion
CommBench shows that multi-device GPU communication remains a clear blind spot for today’s frontier LLMs. Even the strongest model passes under 60% of examples and produces performant code on only a third, while every model collapses to near-zero coverage on specialized libraries such as Mscclpp, ThunderKittens, and the NCCL device API. The failures are not superficial: models hallucinate APIs, misplace synchronization, and ship kernels orders of magnitude slower than reference — gaps that compiler feedback and multi-round retries alone cannot close. Multi-round self-correction helps only on commodity libraries and easier tasks; closing the remaining gap will require targeted post-training on the kind of data CommBench provides. We open-source the dataset and harness to support that effort.
Acknowledgements
We thank Mibura and AMD for sponsoring the testbed for this benchmark.
References
Footnotes
-
Chao Jin et al. MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production. EuroSys, 2026. ↩
-
Shulai Zhang et al. Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts. MLSys, 2025. ↩
-
Changho Hwang et al. MSCCL++: Rethinking GPU Communication Abstractions for AI Inference. ASPLOS, 2026. ↩