Reading OpenAI's MRC Through a UCCL Lens

By: Zhongjie Chen, Xizhi Zhang, Yang Zhou, and the UCCL team
Date: May 26, 2026
MRC (Multipath Reliable Connection) is a new RDMA transport for LLM pretraining from OpenAI, Microsoft, AMD, Broadcom, and NVIDIA.
It is based on the widely used RoCEv2 RC, but addresses many of RC's limitations with per-QP packet spraying, out-of-order delivery, selective retransmission, and multipath congestion control;
it also leverages multi-plane network topology and static SRv6 source routing.
An OCP spec has been released for MRC, with NVIDIA CX-8, AMD Pollara, and Broadcom Thor Ultra RDMA NICs already shipping it.
Through the UCCL lens, we think MRC is not a panacea and cannot effectively support recent MoE communication out of the box because of its lack of support for RDMA atomics.
This blog further compares MRC with alternative solutions including UET, AWS SRD, and our own UCCL-Tran, highlighting the differences among them.
For example, MRC only runs on the very latest silicon (CX-8 / Pollara / Thor Ultra), while UCCL-Tran brings the same multipath, out-of-order delivery, and selective-retransmission power to legacy RDMA NICs.
What Problems Does MRC Address?
LLM training workloads are communication-heavy, and a key bottleneck is scale-out RDMA network performance. The RDMA network can run into many problems, including:
- Flow collisions significantly reduce achievable bandwidth.
- Any switch/link/port failure causes a large blast radius.
- Poor visibility and debuggability with conventional in-network adaptive routing.
The MRC protocol and system design nicely address these problems with massive NIC-managed multipathing, multi-plane network topology, and static SRv6 source routing, achieving stable and performant production training at OpenAI and Microsoft.
Problem #1: Network Flow Collision
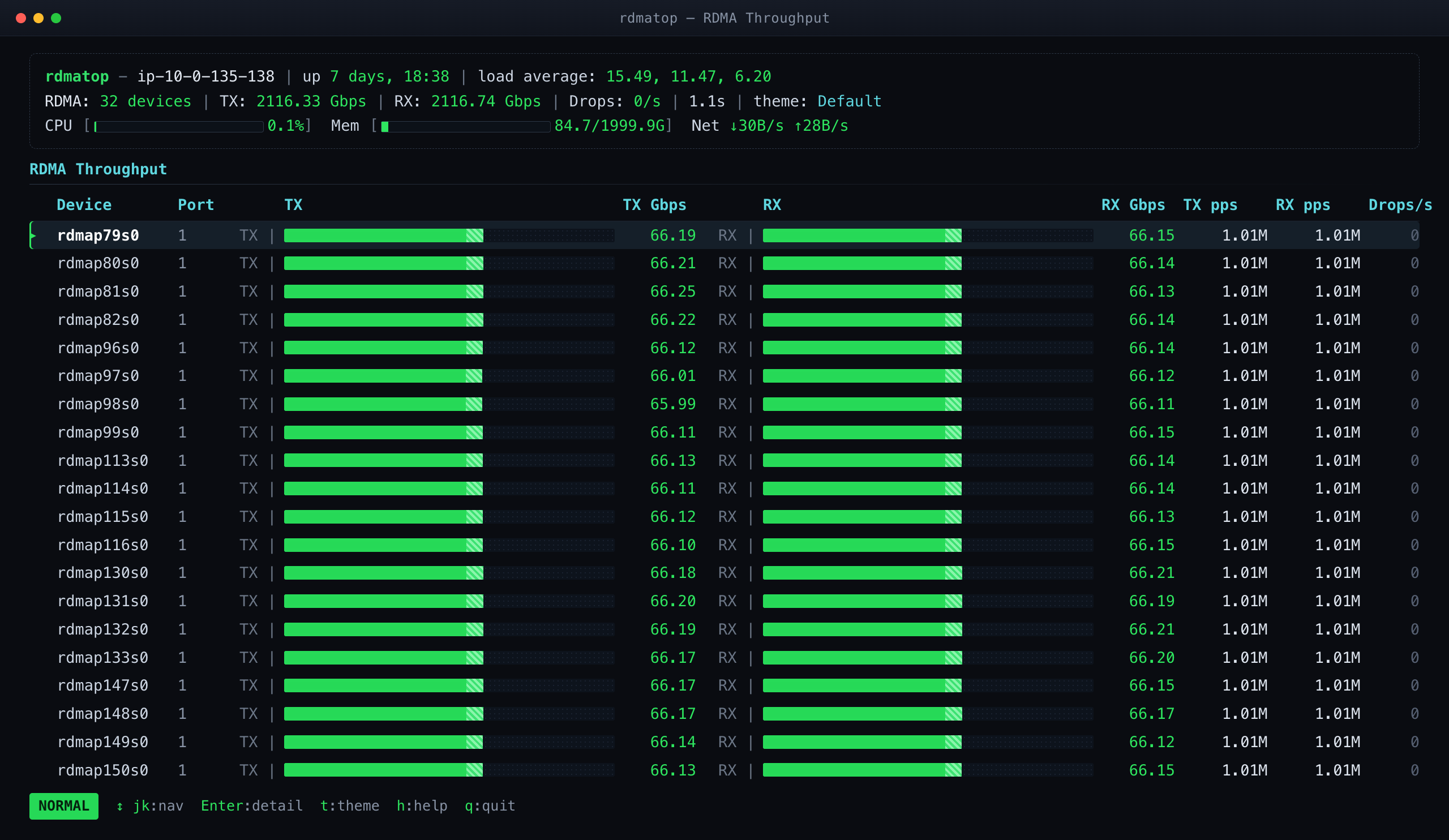
As shown in Figure 1, the problem is that two RDMA flows can collide on the same egress switch port, causing bandwidth degradation. It is rooted in the single-path nature of the widely used RDMA RC QPs (Queue Pairs). We note that our UCCL-Tran 1 paper also studied this problem one year ago.
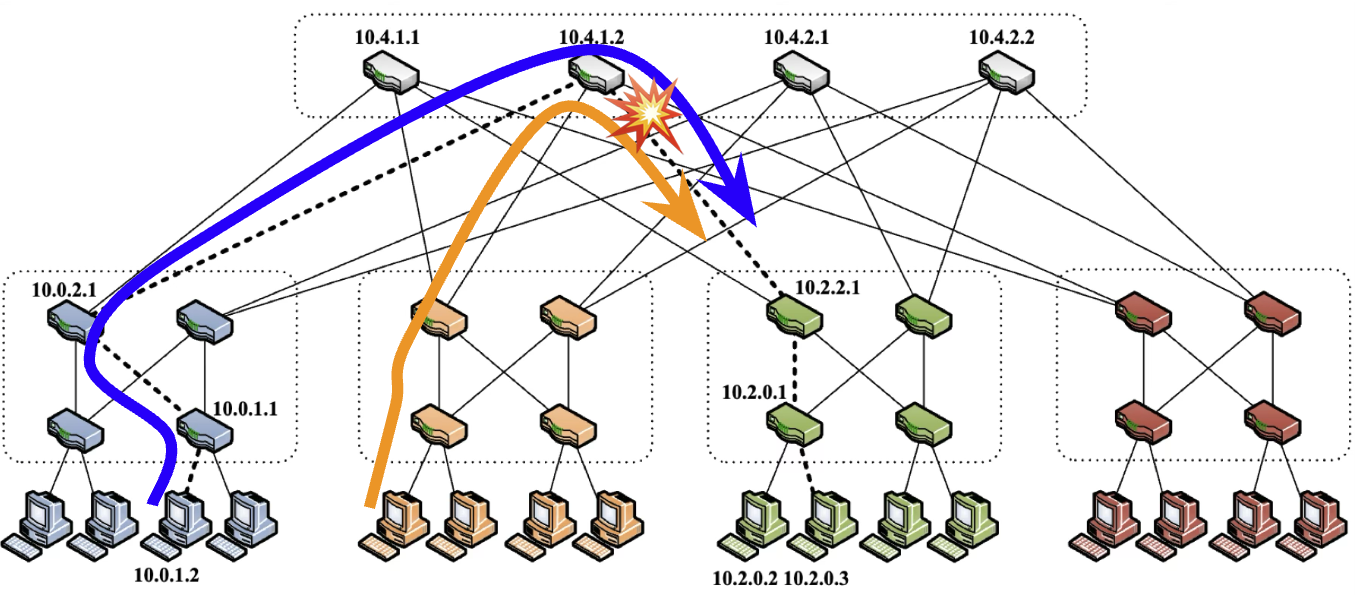 Figure 1: Network congestion can happen because each RDMA flow only goes through a single fixed network path in RoCE, and two flows can collide on the same egress switch port.
Figure 1: Network congestion can happen because each RDMA flow only goes through a single fixed network path in RoCE, and two flows can collide on the same egress switch port.
To address this issue, MRC adopts a suite of techniques:
- Packet spraying. Each MRC QP keeps an active EV set (EV stands for Entropy Value, e.g., src/dst port number), and the NIC picks an EV for each packet so traffic is sprayed across many paths instead of being pinned to one ECMP hash. This directly attacks RC’s single-path-per-QP collision problem. Figure 2 visualizes the process.
- Multipath congestion control. MRC uses UET’s NSCC 2, a sender-driven, SACK-clocked, window-based controller that combines ECN and RTT. It can leave mild single-path congestion to path switching while reducing the congestion window for severe or widespread congestion.
- Selective retransmission + packet trimming. MRC runs without PFC and uses SACK/NACK feedback to retransmit only missing packets. Header-only trimmed packets (generated by switches) trigger fast recovery and help distinguish congestion loss from link-failure loss, avoiding RC’s expensive Go-Back-N behavior.
- Out-of-order placement. Each data packet carries enough RETH information for the receiver NIC to DMA it directly into its final memory location, so reordered sprayed packets can still land correctly.
WRITE_WITH_IMMremains the ordering barrier for completion signaling.
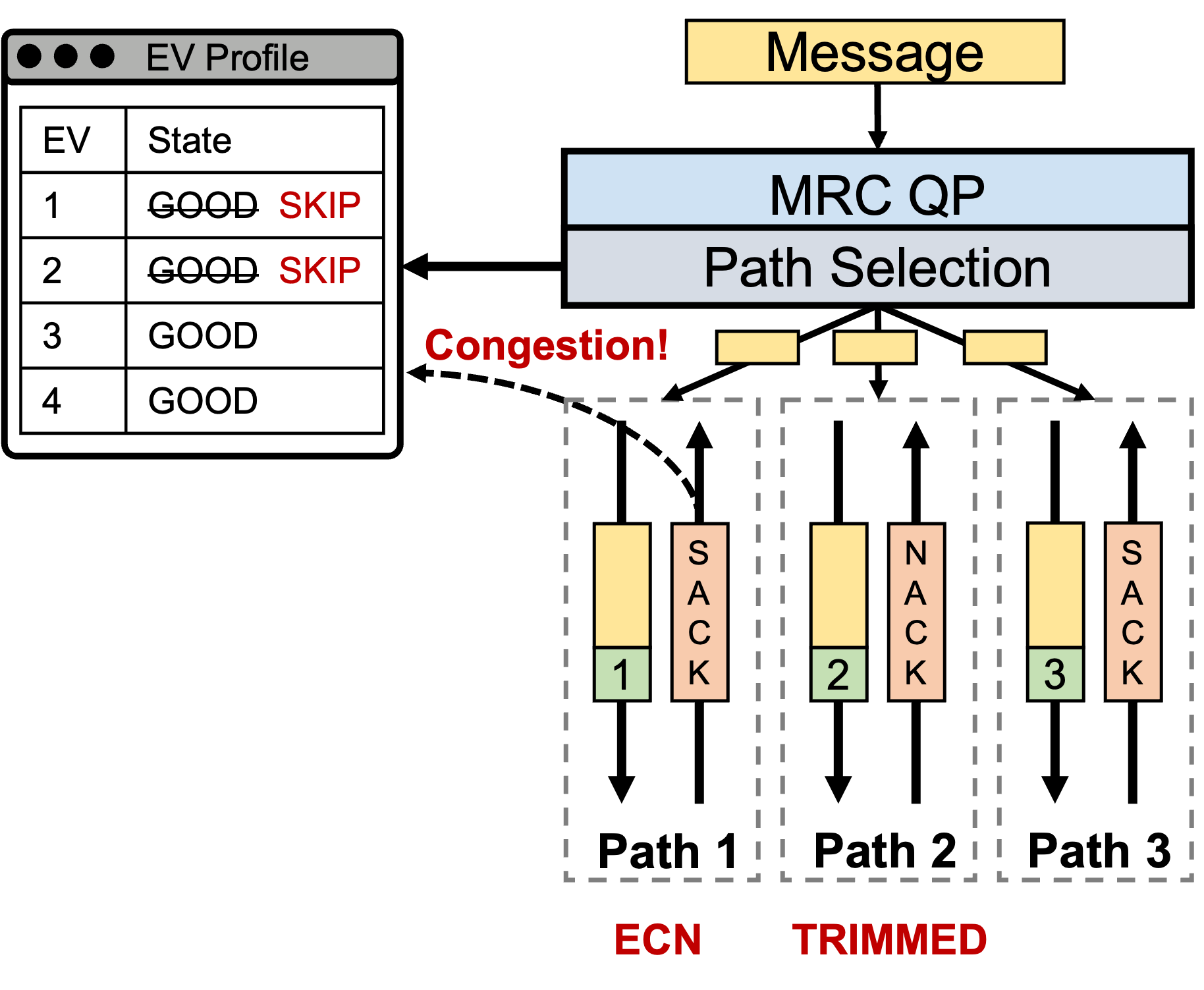
Figure 2: After the message is handed to the MRC QP, the Path Selection stage picks an EV from the QP's active EV set for every packet, then packets get sprayed across network paths in parallel. Feedback from ECN, trimming, SACK, and NACK updates EV state so later packets avoid bad or congested paths.
MRC is not a software protocol — it is implemented in the programmable data plane of three RDMA vendors’ newest silicon: NVIDIA ConnectX-8 (800 Gb/s), AMD Pollara / Vulcano (400/800 Gb/s), and Broadcom Thor Ultra (800 Gb/s).
The host-side API is libibverbs-compatible: applications continue to use the standard verbs surface (QPs, MRs, work-request posting, CQ polling), so existing RDMA stacks like NCCL/RCCL plug in without a new user-space library.
UCCL’s Lens
Many protocol-level bets here mirror decisions UCCL-Tran 1 made in software: per-packet (or per-chunk) spraying across hundreds of logical paths, PFC-off lossy operation, out-of-order DMA placement, and selective retransmission instead of Go-Back-N. The MRC paper is, in many ways, a hardware realization of the same architectural answer — and that is exactly why we find it interesting. UCCL-Tran keeps that same surface in CPU software, so a new CC profile (e.g., receiver-driven EQDS for MoE incast), a new load-balancing policy, or a new loss-tolerance scheme is a code change, not a new tape-out. We see MRC as raising the floor; UCCL-Tran keeps the ceiling open.
Importantly, MRC only runs on the very latest silicon (CX-8 / Pollara / Thor Ultra), while UCCL-Tran brings the same multipath, OoO, selective-retransmit power to the legacy RDMA NICs already deployed in the field — CX-5/6/7, BlueField, EFA, Thor 1/2 — without a hardware refresh, albeit with some design tradeoffs.
Problem #2: Failure Blast Radius
The topology piece is just as important as the transport piece. MRC leans on a key capability of modern NICs — per-lane port breakout — to turn one 800 Gb/s NIC port into 4×200 or 8×100 Gb/s independent network ports, and then builds one Clos plane per lane. This is the crucial distinction from the more familiar multi-rail design (e.g., Alibaba HPN, Meta’s rail-optimized fabrics), where each NIC has a single port that lives in a single rail. Figure 3 compares these two designs.
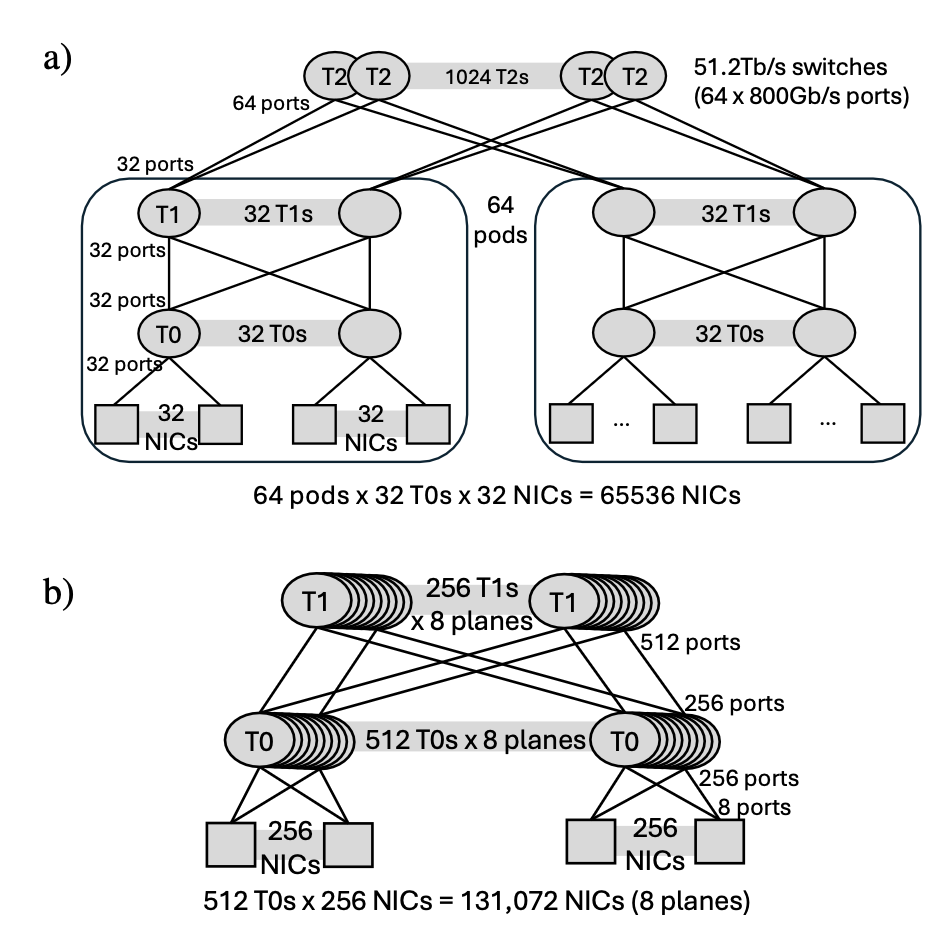
Figure 3: Two ways to wire 100K+ GPUs at full bisection bandwidth. (a) A conventional 3-tier single-plane 800 Gb/s Clos: 64 pods × 32 T0s × 32 NICs = 65,536 NICs, with the longest path crossing 5 switch hops. (b) MRC's 2-tier 8×100 Gb/s multi-plane design: each NIC's 800 Gb/s port is broken into 8 lanes that feed 8 parallel Clos planes built from the same 51.2 Tb/s switches (now seen as 512-port at 100G), reaching 131,072 NICs with the longest path crossing only 3 switch hops, ~2/3 the optics and ~3/5 the switches, and a ~10× smaller blast radius per T0–T1 link loss.
Multi-plane via NIC breakout gets you:
- Two switch tiers for 100K+ GPUs. Each switch effectively has 8× the port count, so a 51.2 Tb/s switch alone can fan out to 512 NICs per tier. Two tiers cover 131,072 GPUs (vs. needing three tiers, oversubscription, or rails for a single-plane design). Two tiers means fewer hops, lower tail latency, fewer optics (~2/3), fewer switches (~3/5), and fewer places for partial failures to hide.
- Failure blast radius shrinks by an order of magnitude. Losing one T0–T1 link removes 1/256 ≈ 0.4% of a NIC’s capacity in an 8-plane network, versus ~3% in a single-plane 800 Gb/s design. Losing one NIC-side port costs 12% of NIC bandwidth, which is survivable: the job keeps running on the remaining planes.
- Locality is much easier. A T0 switch reaches 256 NICs in one hop instead of 32, so collectives like all-gather and ring-attention can exploit T0-local placement far more often, cutting load on the T1 layer.
- Built-in load-balancing leverage. MRC’s per-packet EV spraying directly fills all planes equally; the topology and the transport are co-designed for this.
Multi-plane is also what makes MRC’s per-EV failure detection and recovery practical. Because every EV maps to a specific path through a specific plane, the sender NIC can keep a small EV state table and treat path health as a per-entry property rather than a fabric-wide event. When a packet on EV 42 times out (see the left part of Figure 4 below), that EV is locally marked BAD and immediately removed from the spraying set — the other EVs keep flowing through the remaining planes, so the QP never stalls and the blast radius of a single link fault stays at one entry out of hundreds.
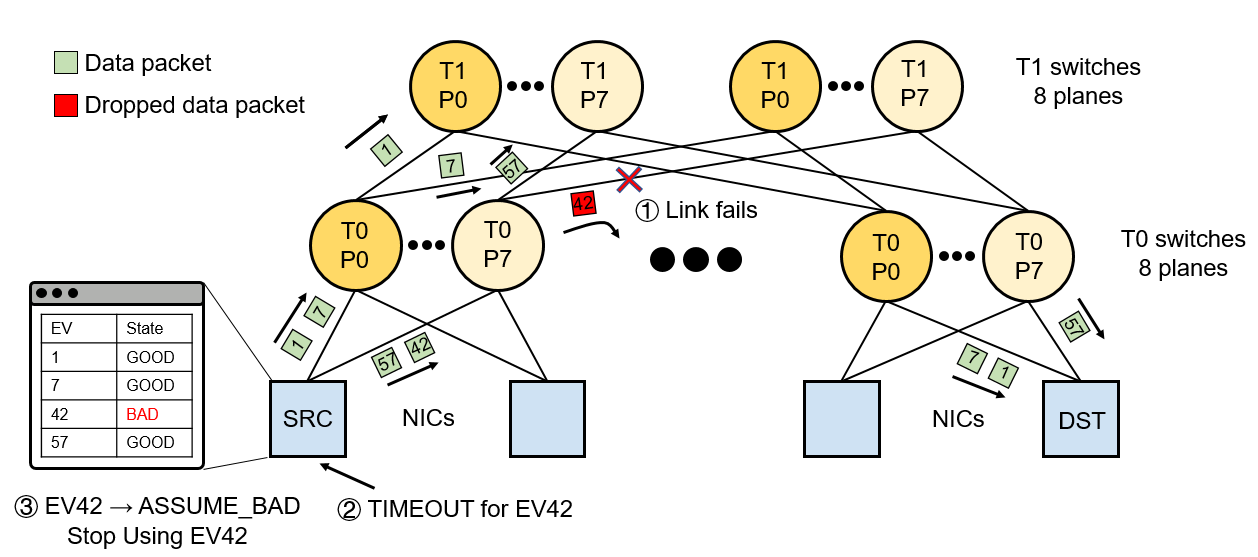
Figure 4: When a link fails, only the EV (path) traversing it is timed out and marked BAD; the other EVs continue to drain traffic through the remaining planes.
Recovery is the symmetric operation. The source NIC periodically emits tiny probe packets on its BAD EVs; as soon as a probe round-trips successfully, the corresponding entry flips back to GOOD and the EV rejoins the active spraying set. There is no fabric-wide reconvergence event, no controller in the loop, and no need to renegotiate the QP — the data plane self-heals at EV granularity, on the order of an RTT after the link comes back.
UCCL’s Lens
We think multi-plane via NIC port breakout is the right direction — it gets you two-tier 100K-GPU reach, an order-of-magnitude smaller failure blast radius, and a topology that composes naturally with packet-level spraying. UCCL-Tran is fully on board with this destination. That said, the UCCL paper makes the equally important practical point that rebuilding the fabric is slow and expensive: new hardware, physical cabling, switch SKUs, optics inventory, and operator playbooks all have to change in lockstep. Most clusters today are single-plane or rail-optimized, and they will remain so for years. Software multipath transports like UCCL-Tran exist precisely to deliver most of the collision-avoidance benefit on the fabric you already have, while operators plan the longer multi-plane refresh. The two efforts are sequential, not competing.
Problem #3: Visibility and Debuggability
The transport story gets most of the airtime, but the operational story is just as important — and arguably the harder thing to replicate. In conventional RDMA deployments with switch-based in-network adaptive routing, a single flow can traverse different switches and links depending on the real-time congestion level. When the step time of a training job doubles, operators cannot easily figure out which switch is the culprit and remove that slow switch.
In OpenAI’s production MRC deployments, dynamic routing is disabled and each EV instead maps algorithmically (via SRv6 uSID templates) to a deterministic physical path. With SRv6 uSID source routing:
- Every EV deterministically encodes a physical path. Probes from a per-node MRC clustermapper agent take exactly the same path an MRC data packet would. There is no dynamic-routing layer in between to lie to you.
- Switches forward SRv6 in the data plane at line rate. This lets every host probe every directly attached T0 (and a sample of T1s) every millisecond. This gives ground truth about forwarding-plane health, independent of the switch control plane.
- Localizing a failure becomes trivial: if T0-loopback probes succeed but T1-loopback probes fail, the bad component is the T0–T1 link.
- Bad-path avoidance becomes more precise and controllable. With SRv6, changing to a replacement EV can deterministically move traffic onto a different physical path, while it cannot make the same guarantee with hash-based ECMP forwarding. With help from MRC clustermapper, SRv6 also lets bad-path avoidance extend beyond a single QP: the denylist can exclude bad EVs from a shared EV Profile, or exclude a failed NIC port so traffic is sprayed across the remaining planes.
UCCL’s Lens
This is the area where MRC has a clear advantage over a pure software transport over commodity ECMP fabrics: source routing gives you deterministic path ↔ EV mapping that we cannot get from hash-based ECMP today. We see this as complementary rather than competitive — a software transport like UCCL-Tran would benefit enormously from being able to carry SRv6 segments on outgoing packets. The OCP MRC spec being open is genuinely good news here.
Is MRC a Panacea for GPU Networking?
MRC is genuinely impressive engineering, but it still has some limitations worth noting, especially when dealing with the GPU-initiated communication commonly used in MoE workloads.
WRITE(w/ IMM) Only Verbs
Only RDMA WRITE and RDMA WRITE_WITH_IMM are on the wire — and this is not just a packaging decision, it falls out of how MRC sprays packets. To allow out-of-order placement, MRC carries an RETH header (remote virtual address + rkey) on every data packet, so each packet is self-contained and can DMA directly into its final memory location. That trick is specific to one-sided WRITEs; it has no natural analog for READ (the responder, not the requestor, would need to spray), for ATOMIC (single-target, serialized), or for two-sided SEND/RECV (no remote address to begin with — the receiver picks the buffer via posted RQ entries).
This matters more than it sounds. The “WRITE-only” pattern is fine for traditional pretraining collectives, but it is awkward for several important newer workloads:
- MoE dispatch / combine (e.g., DeepEP 3) increasingly relies on
ATOMICfetch-and-add for fast, lock-free token-count exchange between senders and experts. Earlier DeepEP versions did useWRITE_WITH_IMM, but that forced the receiver GPU to poll the CQ and re-post RQ entries on the critical path — extra GPU work that competes with the dispatch kernel and is generally regarded as a worse design. The switch to the atomic-based path landed in commit 2d0cf41 one year ago. - KV transfer for PD disaggregation wants
READso that the decode side pulls KV on demand without a coordination round-trip.
WRITE_WITH_IMM With a Small In-Flight Cap
The immediate-data CQE must be delivered to the responder in order with respect to all prior WRITEs on the QP — i.e., a WRITE_WITH_IMM cannot complete until every preceding WRITE has landed.
In a sprayed, out-of-order data plane that means the NIC has to track per-QP barrier state and hold completion resources for every outstanding WRITE_WITH_IMM, which is exactly the kind of bookkeeping that does not scale on-chip.
As a result MRC implementations cap the number of in-flight WRITE_WITH_IMM operations per QP (the spec calls this out and adds a dedicated “Inflight WriteImm limit exceeded” NACK code).
Workloads that try to use WRITE_WITH_IMM as a fine-grained signaling primitive — one immediate per chunk — will hit this cap before they hit bandwidth.
Last-Hop Incast
NSCC is solid, but in practice MRC leans on packet trimming + selective retransmit + receiver-side backpressure to absorb receiver-side bursts. For workloads with very skewed receiver-side hot spots (MoE serving with hot experts, PD disaggregation, irregular all-to-all), a receiver-driven scheduler (e.g., EQDS-style 4) is a strictly better answer — and it’s unclear whether MRC can support this.
Built into the Newest Silicon Only
MRC ships on CX-8, AMD Pollara/Vulcano, and Broadcom Thor Ultra. The very large installed base of CX-5/6/7, BlueField, EFA, and Thor 1/2 cannot run MRC at all — a fleet-wide upgrade is on the order of years and many billions of dollars.
Tradeoff Summary: MRC vs. UEC/UET vs. AWS SRD vs. UCCL-Tran
MRC, UEC/UET, AWS SRD, and UCCL-Tran all answer the same question — “how do we move ML traffic across a large GPU fabric reliably, with multipath, no PFC, and graceful loss recovery?” — but they make very different bets on where the transport lives and how open it is. MRC pushes the answer into a new generation of merchant silicon under an open OCP spec; UEC standardizes a broader Ethernet transport through an open multi-vendor specification 2; AWS SRD bakes a similar answer into the closed Nitro / EFA data plane, tightly co-designed with the AWS VPC fabric 5; UCCL-Tran keeps the answer in CPU software, so it can ride on the legacy RDMA NICs already deployed in the field.
The table below lines up the design choices side by side so the tradeoffs — performance ceiling, hardware dependency, openness, programmability, observability, and time-to-ship — are easy to compare.
| MRC | UEC/UET | AWS SRD | UCCL-Tran | |
|---|---|---|---|---|
| Where transport runs | NIC ASIC/firmware data plane | NIC ASIC/firmware data plane | Nitro/EFA NIC data plane | Host CPU control path + RDMA UC/RC/UD data path |
| Hardware requirement | CX-8 / Pollara·Vulcano / Thor Ultra only | UET-capable NICs | AWS EFA-enabled instances only (Nitro) | Runs on legacy NICs: CX-5/6/7, BlueField, EFA, Thor 1/2 |
| Wire format | Open OCP MRC spec | Open UET specification | Closed, AWS-proprietary | Open |
| Spraying granularity | Per-packet | Per-packet | Per-packet | Per-chunk for UC/RC, per-packet for UD |
| Ordering model | OOO packet delivery, OOO message delivery, WRITE_WITH_IMM enforces order | OOO packet delivery with transport-level recovery | OOO packet delivery, OOO message delivery | OOO packet/chunk delivery, In-order/OOO message delivery are both supported |
| Verb surface | libibverbs, WRITE + WRITE_WITH_IMM only | UET transport / ULP APIs, not necessarily drop-in RC verbs | libfabric; SEND/RECV + WRITE + READ, no ATOMIC | All verbs the underlying NIC exposes (incl. WRITE, READ, ATOMIC, SEND/RECV) |
| Congestion control | UET NSCC (ECN + RTT, window-based) | UET NSCC, RCCC, and hybrid modes | AWS-proprietary, Cubic-like, designed for VPC fabric | RTT-based, pluggable |
| Loss recovery | SACK + packet trimming, in-NIC | SACK + packet trimming, in-NIC | Selective retransmit, in-NIC | SACK + selective retransmit, in software |
| PFC | Off (lossy by design) | Off (lossy by design) | Off (lossy by design, VPC fabric) | Off (lossy by design) |
| Packet spray | SRv6 uSID source routing | Entropy-based multipath over Ethernet | Multi-path over AWS VPC (hash-based, fabric-managed) | EV → ECMP hash |
| Path selection | Programmable | Standardized hooks, implementation-dependent | Programmable | Programmable |
| Topology assumption | Co-designed with multi-plane port-breakout fabric | Ethernet fabric, potentially multi-rail or multi-plane | Co-designed with AWS VPC / Nitro fabric | Works on whatever fabric you already have (single-plane, rail, multi-plane) |
| Time to ship a new idea | New silicon tape-out + spec revision + limited programmability | Spec revision + vendor NIC implementation | New Nitro firmware/silicon under AWS control | Code change |
| Openness / portability | Open spec (OCP), multiple vendors | Open standard, multi-vendor target | AWS-only, not portable off AWS | Open, runs on any commodity RDMA/Ethernet NIC |
| Observability | Limited by hardware interface | Open standard, but hardware telemetry remains vendor-dependent | Limited by hardware interface, AWS-controlled telemetry only | Highly observable in software |
References
Footnotes
-
Yang Zhou, Zhongjie Chen, Ziming Mao, ChonLam Lao, Shuo Yang, Pravein Govindan Kannan, Xizhi Zhang, Jiaqi Gao, Yilong Zhao, Yongji Wu, Kaichao You, Fengyuan Ren, Zhiying Xu, Costin Raiciu, Ion Stoica. UCCL-Tran: An Extensible Software Transport Layer for GPU Networking. USENIX OSDI, 2026. https://arxiv.org/pdf/2504.17307 ↩ ↩2
-
Ultra Ethernet Consortium. Ultra Ethernet Specification v1.0. 2025. https://ultraethernet.org/wp-content/uploads/sites/20/2025/06/UE-Specification-6.11.25.pdf ↩ ↩2
-
DeepSeek-AI. DeepEP — An efficient expert-parallel communication library. GitHub, 2025–2026. https://github.com/deepseek-ai/DeepEP ↩
-
Olteanu, Vladimir, Haggai Eran, Dragos Dumitrescu, Adrian Popa, Cristi Baciu, Mark Silberstein, Georgios Nikolaidis, Mark Handley, and Costin Raiciu. An edge-queued datagram service for all datacenter traffic. USENIX OSDI, 2022. https://www.usenix.org/system/files/nsdi22-paper-olteanu.pdf. ↩
-
Leah Shalev, Hani Ayoub, Nafea Bshara, and Erez Sabbag. A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC. IEEE Micro, 2020. https://ieeexplore.ieee.org/document/9189994 ↩