mKernel: Fast Multi-GPU, Multi-Node Fused Kernels

By: Ziming Mao, and the UCCL team
Date: May 25, 2026
mKernel is a collection of fast multi-GPU, multi-node fused kernels that enable intra-node communication, inter-node RDMA, and compute inside a single persistent kernel.
Host-driven GPU communication is increasingly the bottleneck.
AI training and serving are limited by GPU communication. In production, communication can consume 43.6% of the forward pass and 32% of end-to-end training time on GPUs [1], and inter-device communication can account for up to 47% of total execution time across popular MoE models and frameworks [2].
The traditional approach is host-driven: the CPU runs the control path, calls into a library (NCCL/NVSHMEM), and the library issues the collective. It increasingly does not align with modern AI workloads for two reasons:
- CPU-mediated control creates more visible pipeline bubbles as GPUs get faster. Accelerators are getting faster, but not the CPU. Rack-scale GPU systems now expose hundreds of PFLOP/s to exaFLOP/s-class compute: a GB300 NVL72 rack integrates 72 Blackwell Ultra GPUs and 36 Grace CPUs, delivering 720 PFLOP/s FP8/FP6, 1.44 EFLOP/s FP4 Tensor Core performance, and 130 TB/s of all-to-all intra-rack NVLink bandwidth [4]. At these speeds, even microsecond-scale host orchestration overhead — a cudaLaunchKernel, a CPU-side “all writes done” check, an inter-stream event — shows up directly as pipeline bubbles.
- Fine-grained overlap is needed to maximize performance. Host-driven systems overlap by launching compute and communication kernels on separate streams, but their decisions are still made at coarse kernel boundaries — leaving more finer-grained overlap on the table.
The natural answer is GPU-driven communication: let the GPU itself trigger fine-grained transfers, where communication is fused into the same kernel as the compute. However, most existing fused kernel libraries operate under a single node, if not, a single GPU.
mKernel is our attempt at the missing piece: GPU-driven, fused kernels that deliver fine-grained compute–communication overlap across both intra-node NVLink and inter-node RDMA, while staying portable across various networking backends (ConnectX-7, AWS EFA, and more on the way).
What mKernel does
mKernel is a small, focused library of persistent CUDA kernels — each of which fuses intra-node NVLink communication, inter-node RDMA, and dense compute into a single kernel.
- Multi-GPU + multi-node, in one kernel. Intra-node NVLink and inter-node RDMA both live inside the same persistent kernel.
- Fine-grained intra-kernel overlap. Compute and communication overlap at tile/chunk granularity, covering both the intra-node and inter-node GPU communication.
- Persistent kernel with SM specialization. CTAs self-assign roles, such as
compute,intra-comm,inter-send,inter-reduce. The split (e.g. number of SMs dedicated to each role) is tunable per shape. - GPU-driven networking, built on
libibverbs. mKernel uses GPU-initiated RDMA writes without depending on NCCL or NVSHMEM. We find that writing the communication backend from scratch is helpful to maximize performance as well as cater to heterogenous networking devices.
The five fused kernels
| Kernels | What it fuses | Description |
|---|---|---|
| AllGather + GEMM | AllGather → GEMM | Each rank holds a shard of A. While ranks gather peers’ shards over NVLink/RDMA, the local GEMM consumes tiles as soon as they arrive. |
| GEMM + AllReduce | GEMM → AllReduce | Computes C = A @ B and reduces partial outputs across all ranks in one launch. |
| MoE Dispatch + GEMM | All-to-All dispatch → grouped GEMM | Routes MoE tokens to their expert ranks (intra-node NVLink + inter-node all-to-all) and runs the per-expert grouped GEMM in the same kernel. |
| Ring Attention | Ring KV exchange → FlashAttention | Sequence-parallel attention across ranks: each step rotates a KV chunk around the ring while the local FlashAttention consumes the previously-received chunk. |
| GEMM + ReduceScatter | GEMM → ReduceScatter | Computes C = A @ B and reduce-scatters the output across ranks. Each output tile is reduced and forwarded to its owning rank as soon as it’s produced |
Evaluation setup
We evaluate mKernel on two 2-node × 8-H200 clusters that differ only in the inter-node fabric (CX7, EFA).
| Testbed | Nodes × GPUs | Intra-node | Inter-node transport | NIC |
|---|---|---|---|---|
| AWS EFA | 2 × 8 H200 | NVLink | AWS EFA / SRD | 16 × 200 Gb/s EFA per node |
| ConnectX-7 | 2 × 8 H200 | NVLink | InfiniBand | 8 × 400 Gb/s NVIDIA ConnectX-7 per node |
mKernel is benchmarked against several baselines for each workload, including: NCCL, Triton-distributed, Flux, Mercury, MagiAttention, Transformer-Engine, and ring-flash-attention. We are still doing further benchmarking on larger scale.
Results on AWS EFA
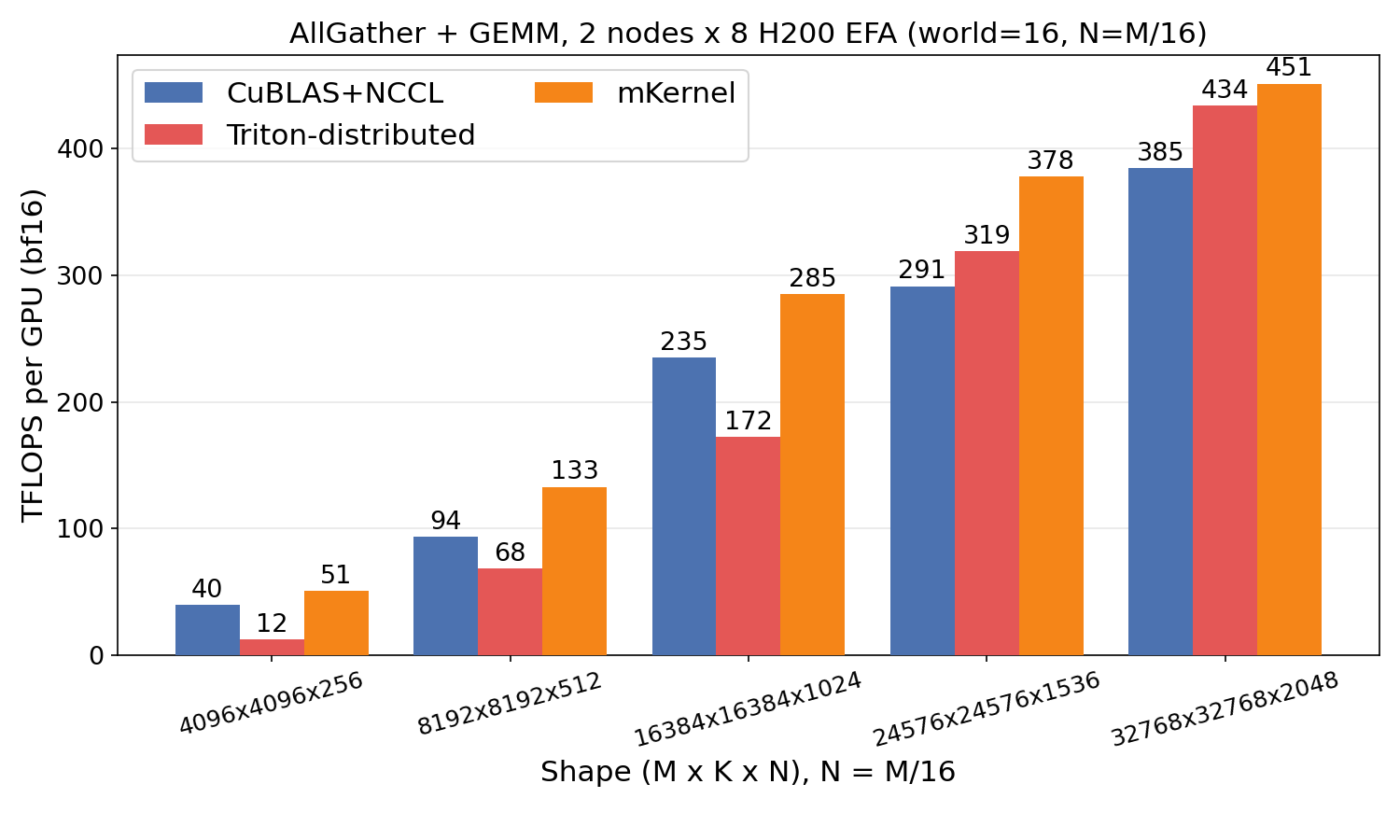 AllGather + GEMM
AllGather + GEMM
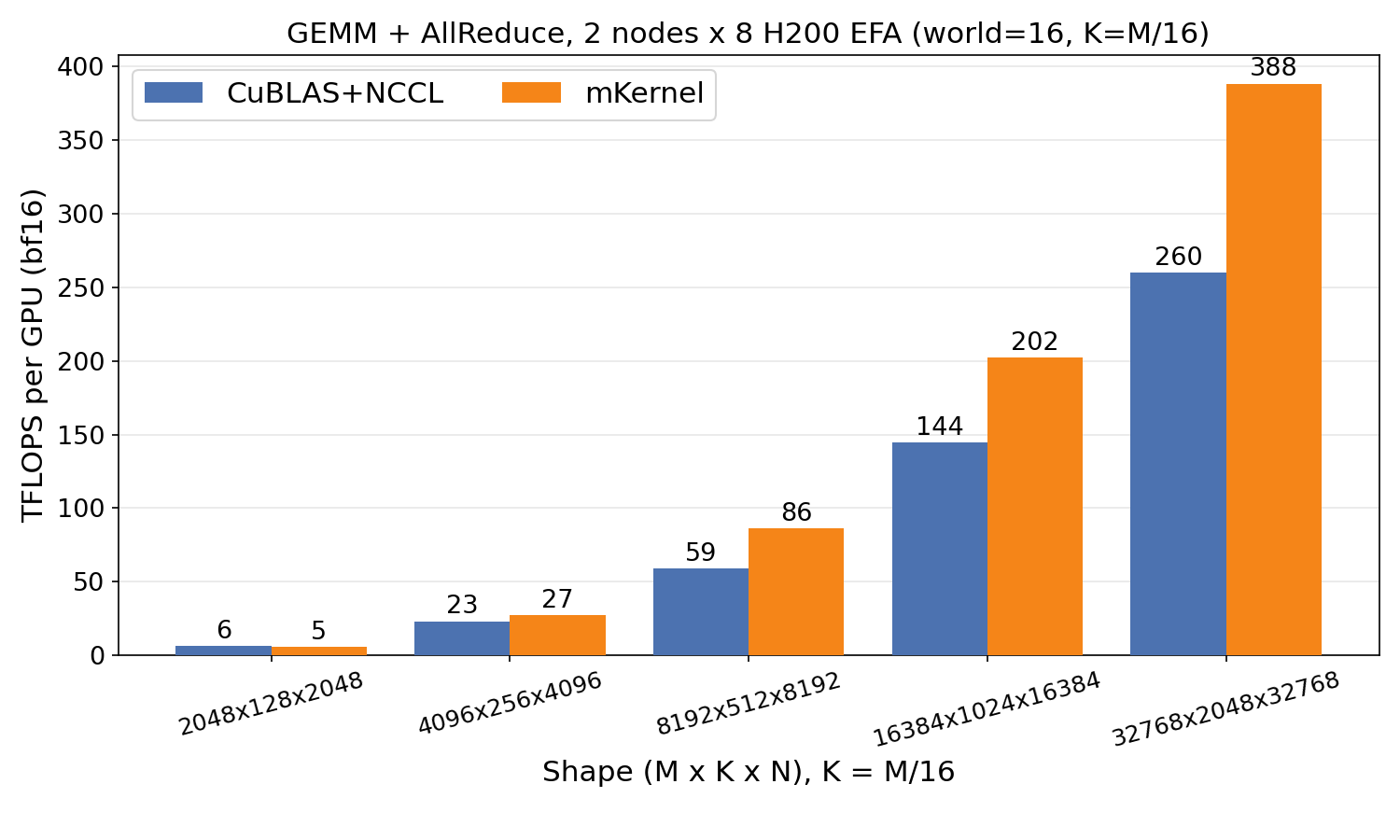 GEMM + AllReduce
GEMM + AllReduce
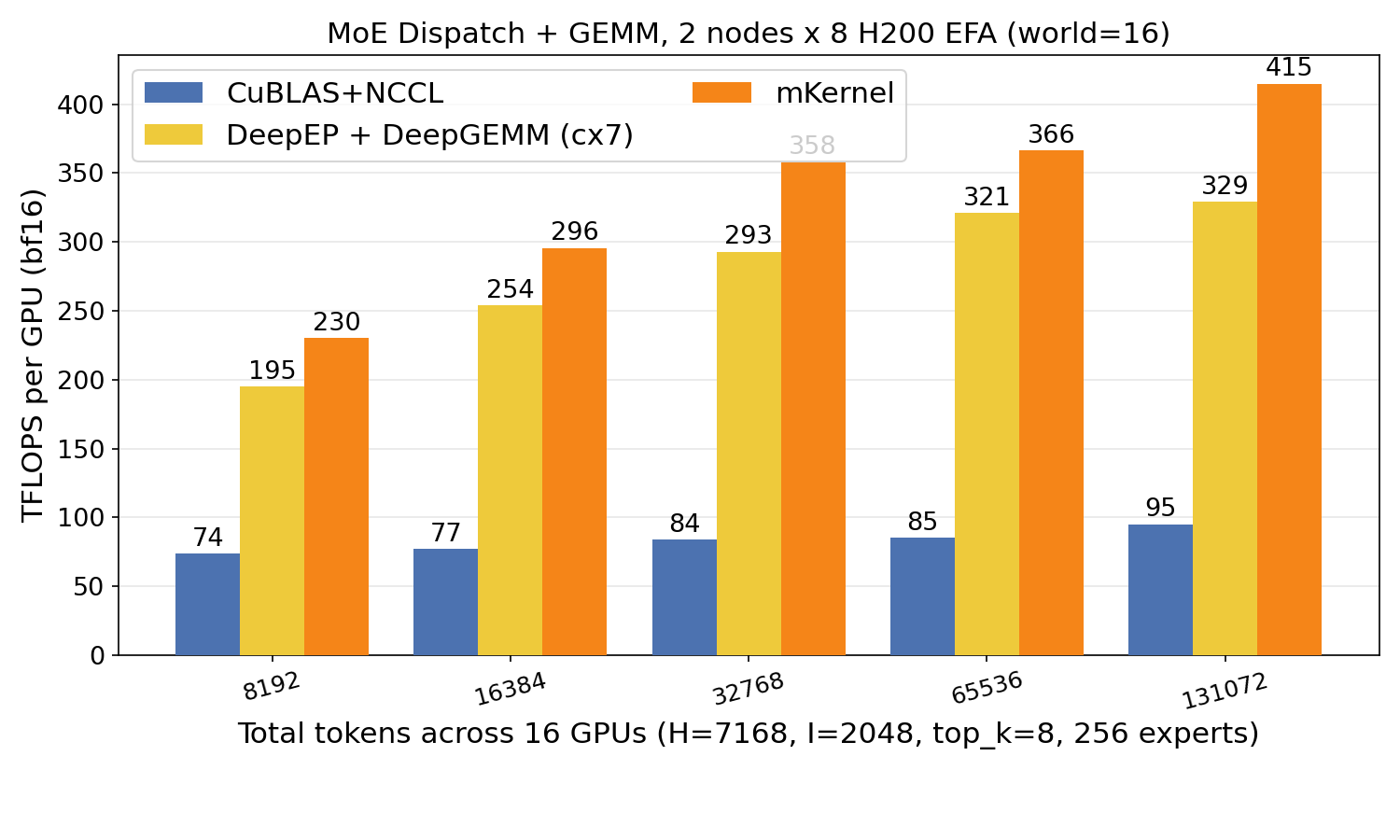 MoE Dispatch + GEMM
MoE Dispatch + GEMM
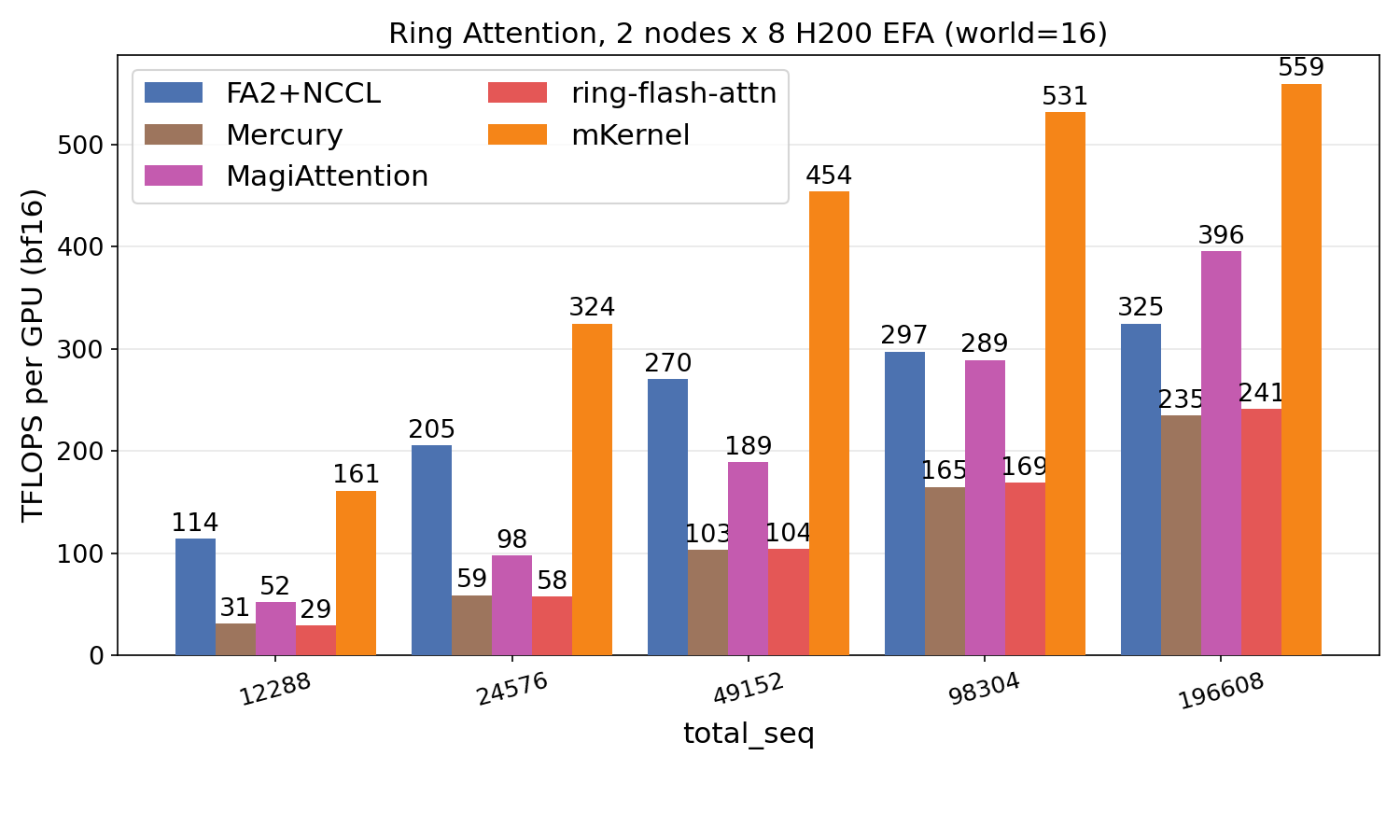 Ring Attention
Ring Attention
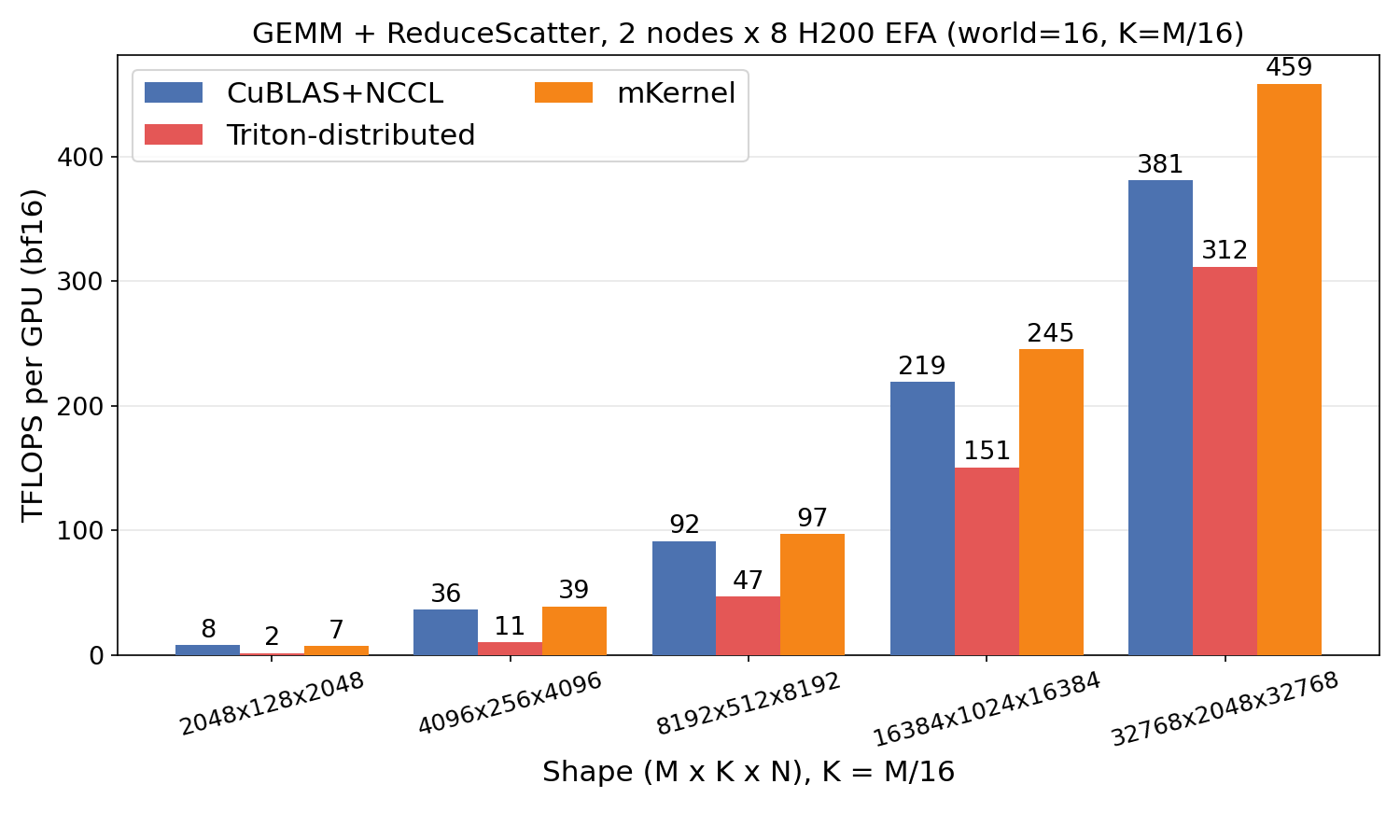 GEMM + ReduceScatter
GEMM + ReduceScatter
Results on ConnectX-7
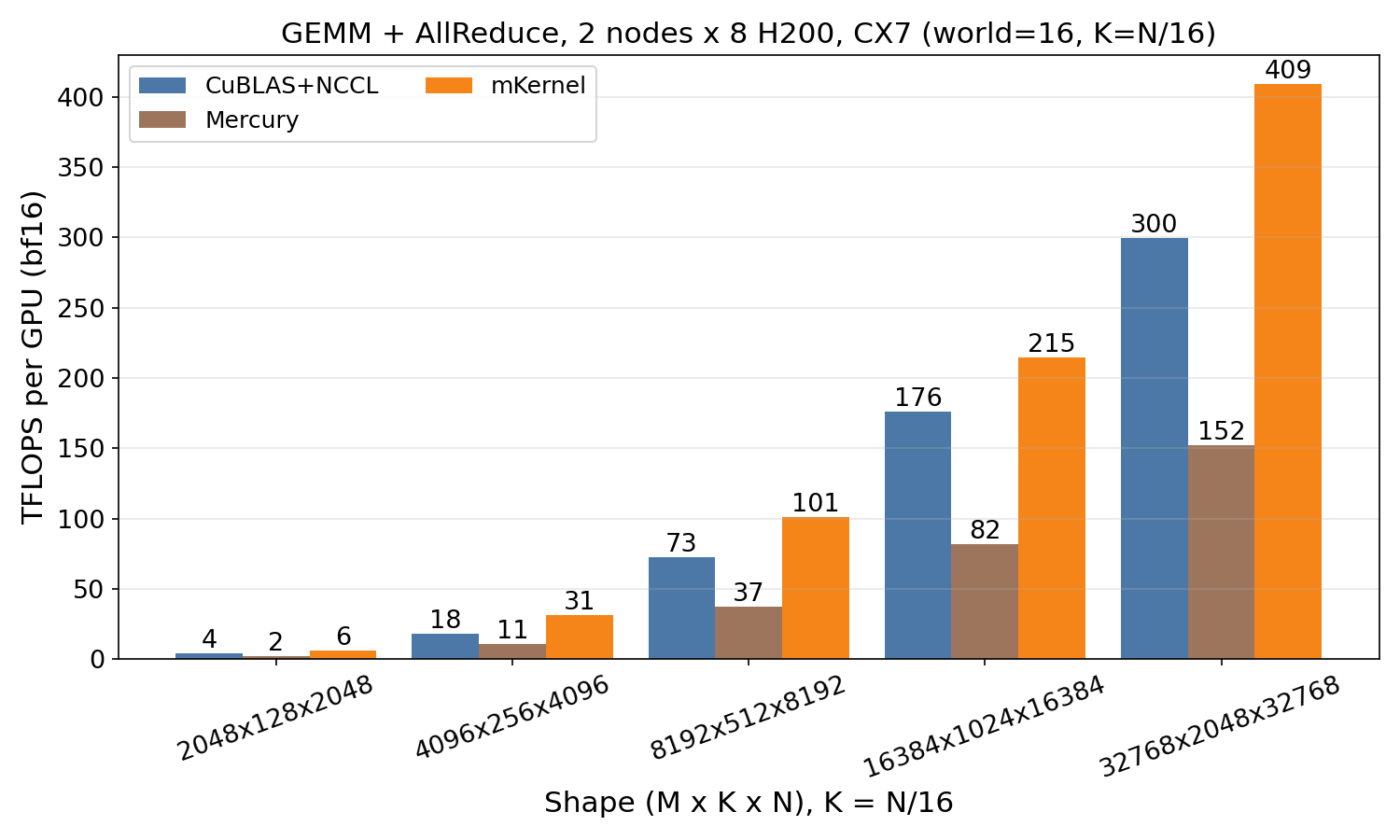 GEMM + AllReduce
GEMM + AllReduce
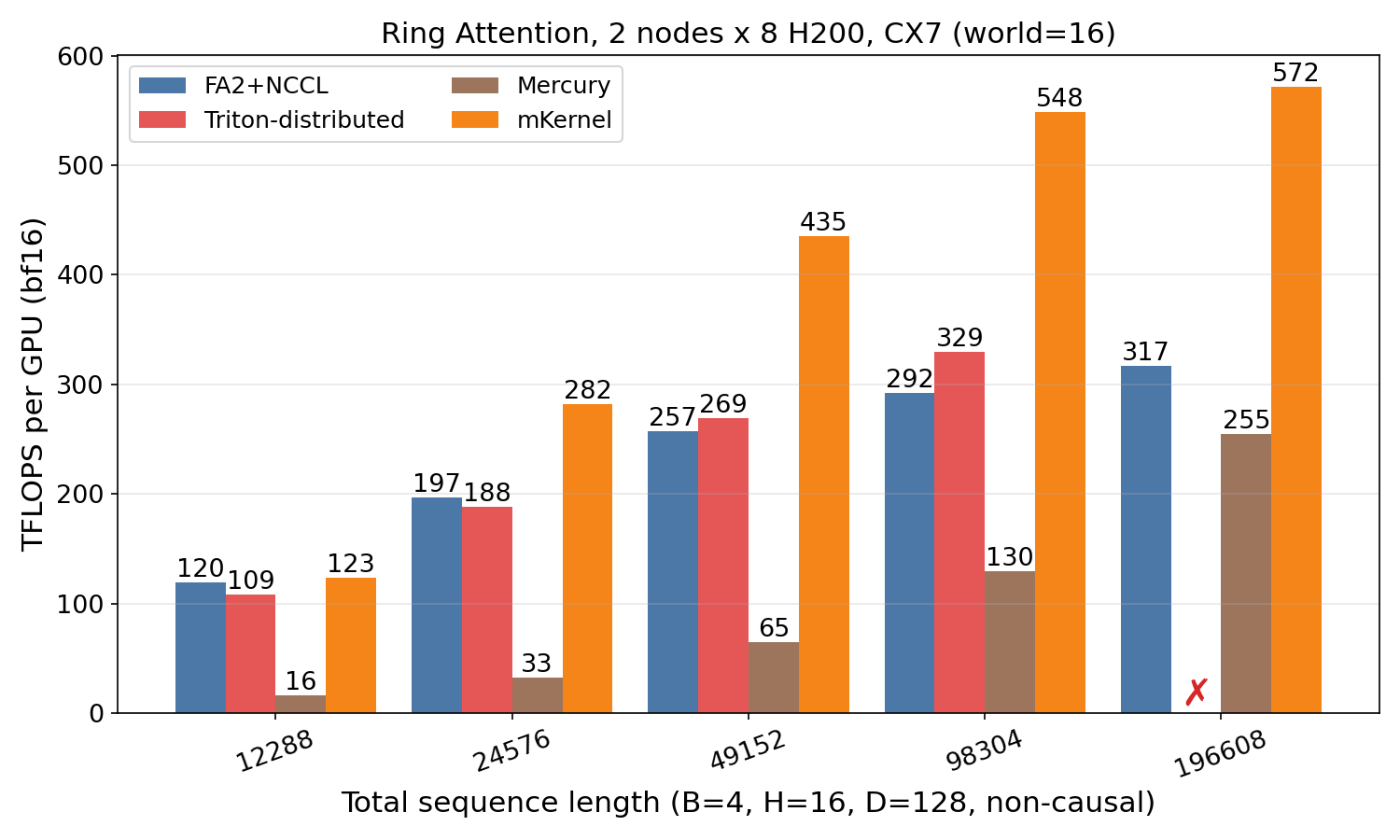 Ring Attention
Ring Attention
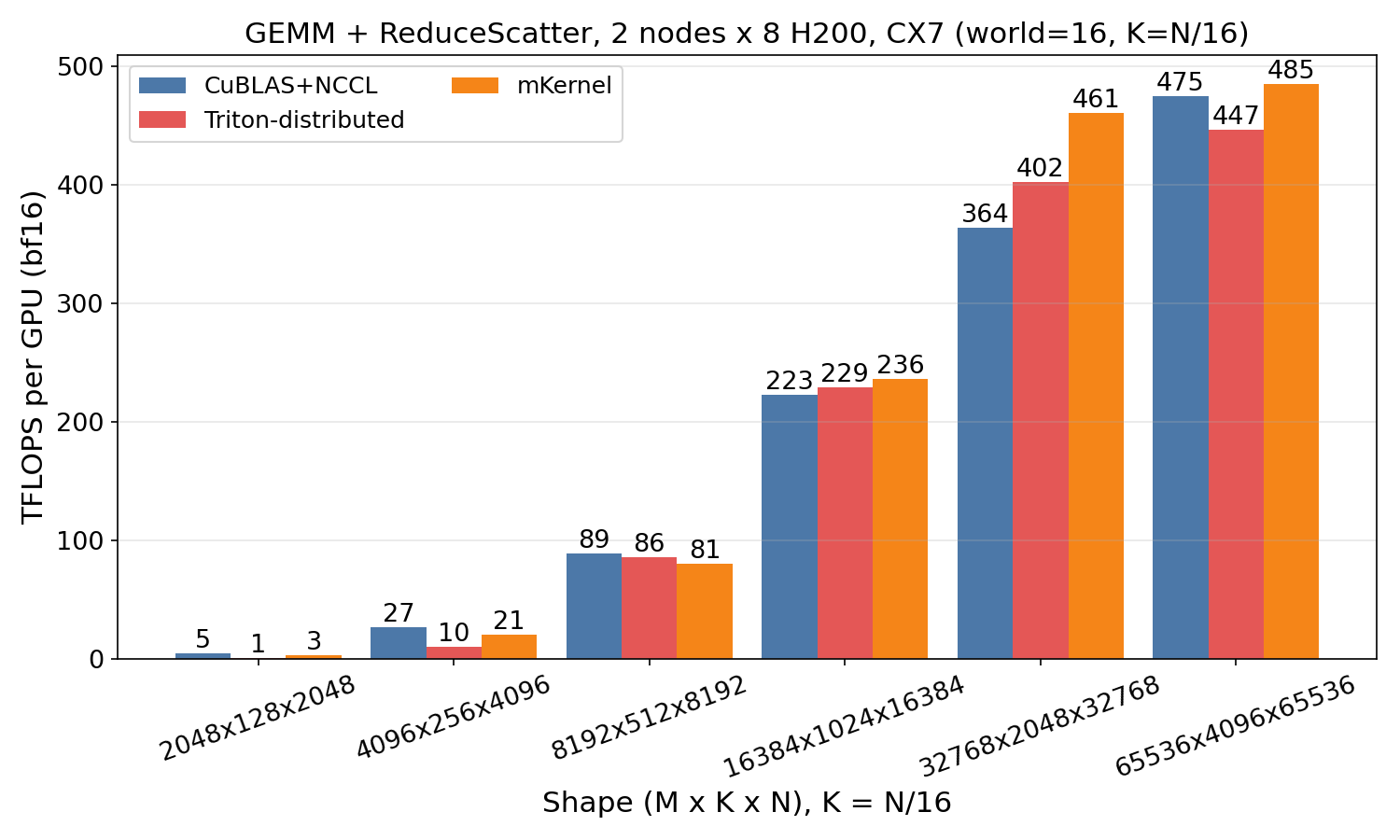 GEMM + ReduceScatter
GEMM + ReduceScatter
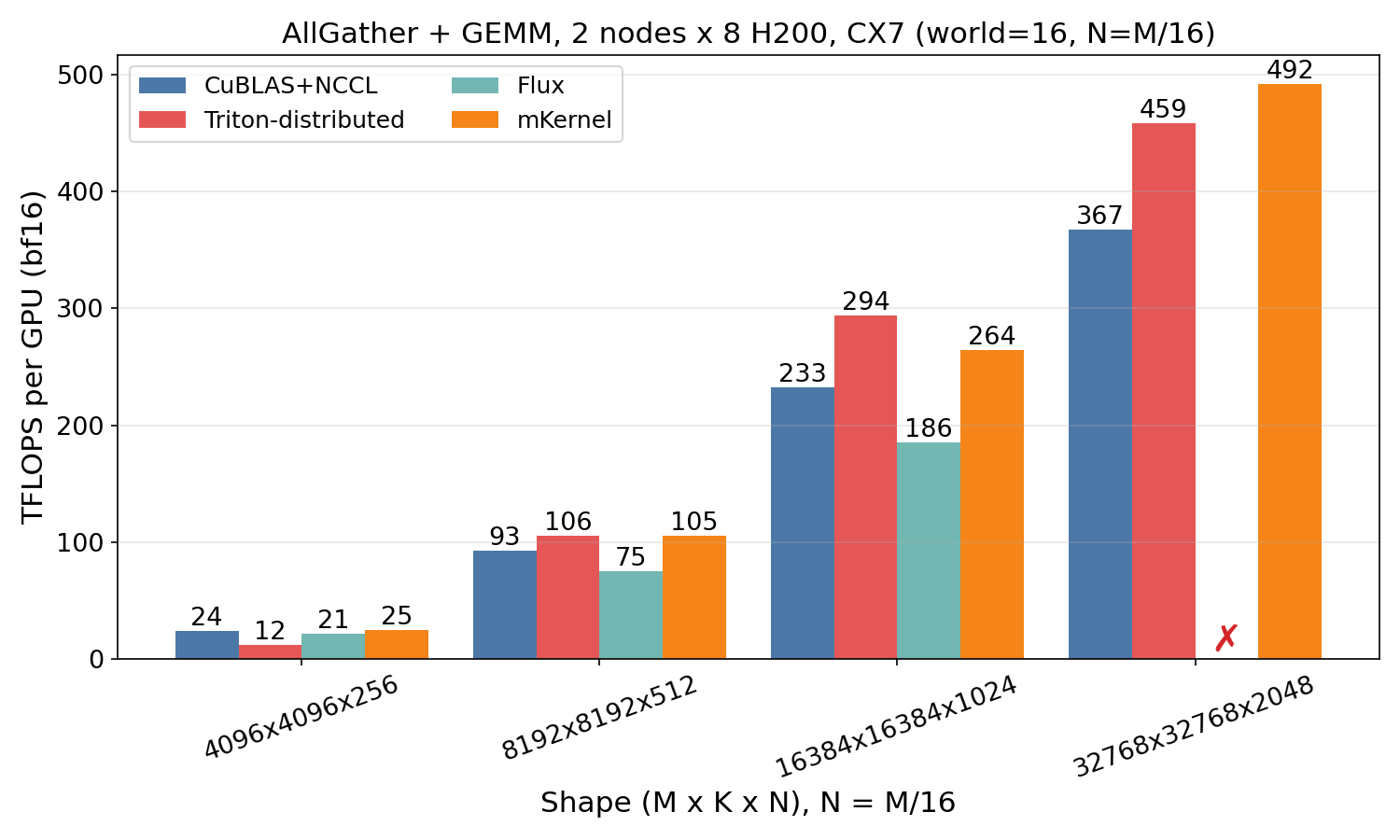 AllGather + GEMM
AllGather + GEMM
Roadmap
- ✅ Fused, GPU-driven multi-node kernels (AG+GEMM, GEMM+AR, dispatch+GEMM, ring attention, GEMM+RS).
- ✅ ConnectX-7 and AWS EFA backends.
- 🚧 Full support for heterogeneous accelerators and NICs, with topology-aware accelerator/NIC discovery, placement, and routing.
- 🚧 Inter-node megakernels: collapsing several fused steps into a single megakernel that spans an entire transformer layer.
- 🚧 Blackwell GPU support.
References
- Chao Jin et al. MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production. EuroSys, 2026.
- Shulai Zhang et al. Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts. MLSys, 2025.
- Google Cloud. TPU7x (Ironwood). Google Cloud Documentation, 2026.
- Microsoft Azure. ND GB300-v6 Sizes Series. Azure Virtual Machines Documentation, 2026.



